Spec Driven Development
Plus OpenAI's creative strategy, MCP server understands lambda's event sourcing, Why you don't like OOP and more
As a developer, you have your toolset: cli scripts, IDE settings, plugins, etc. AI coding assistants are tools like any other. This means that it is up to you, the developer, to find out the best way for you to use them.
The AI tooling continues to evolve at a fast pace, complementing the capabilities of new models. Cursor, WindSurf, and Visual Studio Code tend to release monthly upgrades that offer you improved or completely new experiences.
On the other side, developers create their custom instruction files (copilot-instructions.md, AGENT.md, CLAUDE.md, and so forth) to capture your preferences.
Dealing with larger code bases and keeping consistency still seems to be a struggle, which increases as you factor in that many developers are working on the same product.
That is an area where Spec-Driven Development appears as an interesting proposal. In a nutshell, the idea is to ground the development, assisted by the LLM, in a collection of documents capturing the requirements, both functional and non-functional. This way, you have a process to follow and these documents are continuously maintained, helping with both consistency and collaboration.
Since those documents become artifacts saved with your source version control, they can be tracked, evolved, and shared.
In a recent article, I covered SpecKit, which establishes a 5-step process that delivered interesting results for both greenfield and brownfield projects that I experimented with.
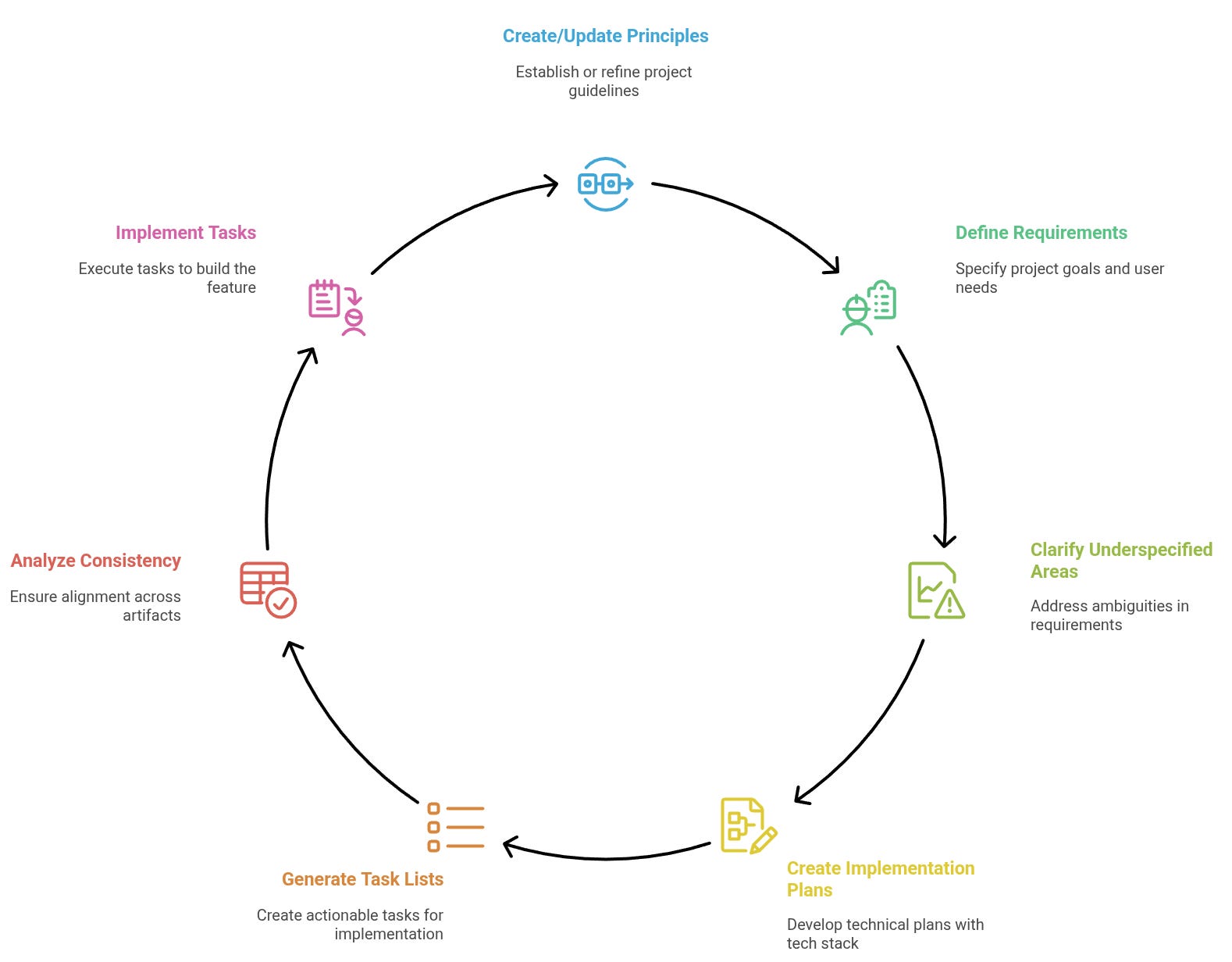
It works by having a series of custom scripts, templates, and prompt files. As you go through the process, it uses those prompts to perform several actions, from capturing your standards and conventions, to performing research, data modeling, to breaking the feature you specified into user stories and phases.
Ultimately, it goes and implements the code following your specification. In the example below, each 00X iteration represents one session focused on addressing the new/updated feature that I requested.
It is important to mention that it is still not perfect, and even with the specification, I noticed it ignored certain aspects, but it was a minority. In retrospect, it mainly happened in the first iteration, where it created the entire working application, serving as a reminder that slicing the requirements into separate sessions helps.
AI
OpenAI’s Rising Tide Strategy
If you have been following the news, you are probably aware of many deals involving OpenAI, including:
OpenAI is getting the rights to acquire up to 10% of AMD’s stock.
NVIDIA intends to invest up to $100 billion in OpenAI as the new NVIDIA systems are deployed.
I can´t think of a better way to describe it than this video
In all seriousness, it seems unavoidable not to think of the circular nature of this strategy, and, oddly, most are ok with it. Some voices echo the resemblance to the dot-com bubble, while others dismiss it, given the fact that the involved companies actually have revenues and business plans with profitability in mind.
This article offers a good summary of why there is a potential for those deals to be beneficial and why OpenAI needs to be creative at this point.
I guess all that is left is to figure out how to position ourselves, as professionals and investors, in this scenario, and hope the cycle adjusts itself without a major correction down the line.
Introducing AWS Lambda event source mapping tools in the AWS Serverless MCP Server
MCP servers are one of the most overlooked ways to extend the capabilities of your AI-assisted workflow.
There are many out there and they usually offer you tooling capabilities to perform additional actions, such as connecting to your database to retrieve contents or structure and use that information to generate code.
A cool usage that some MCP servers are offering is to provide an “expert” look at design, analysis and troubeshooting aspects. I covered the DynamoDB option here, and recently AWS released an updated version of their Serverless MCP with tooling support to help you with the event sourcing part of lambda workloads.
Event sourcing in the serverless context refers to the triggers that will end up invoking your lambda functions. They can be various, from API Gateways, DynamoDB streams, SQS and Kafka to name a few. Each event source has some different configuration capabilities that you have to cater as you develop your application.
For example, if you have an event source and is experiencing some delays in the processing, you can explain what is happening and the MCP will assess your configuration and provide a recommendation.

The results of this analysis are usually better than the LLM coming with a generic suggestion just based on its training material.
Another advantage of this MCP server is that it can also generate the SAM templates, IAM policies, and security groups based on your interactions. This ties the design and execution together for a quicker feedback cycle.
An important thing to note is that the MCP server works in read-only mode by default, which means it will not make modifications on your behalf. I can’t stress enough that this is something you should care about in any MCP server you use.
Developer
A new developer joins GitHub every second as AI leads TypeScript to #1
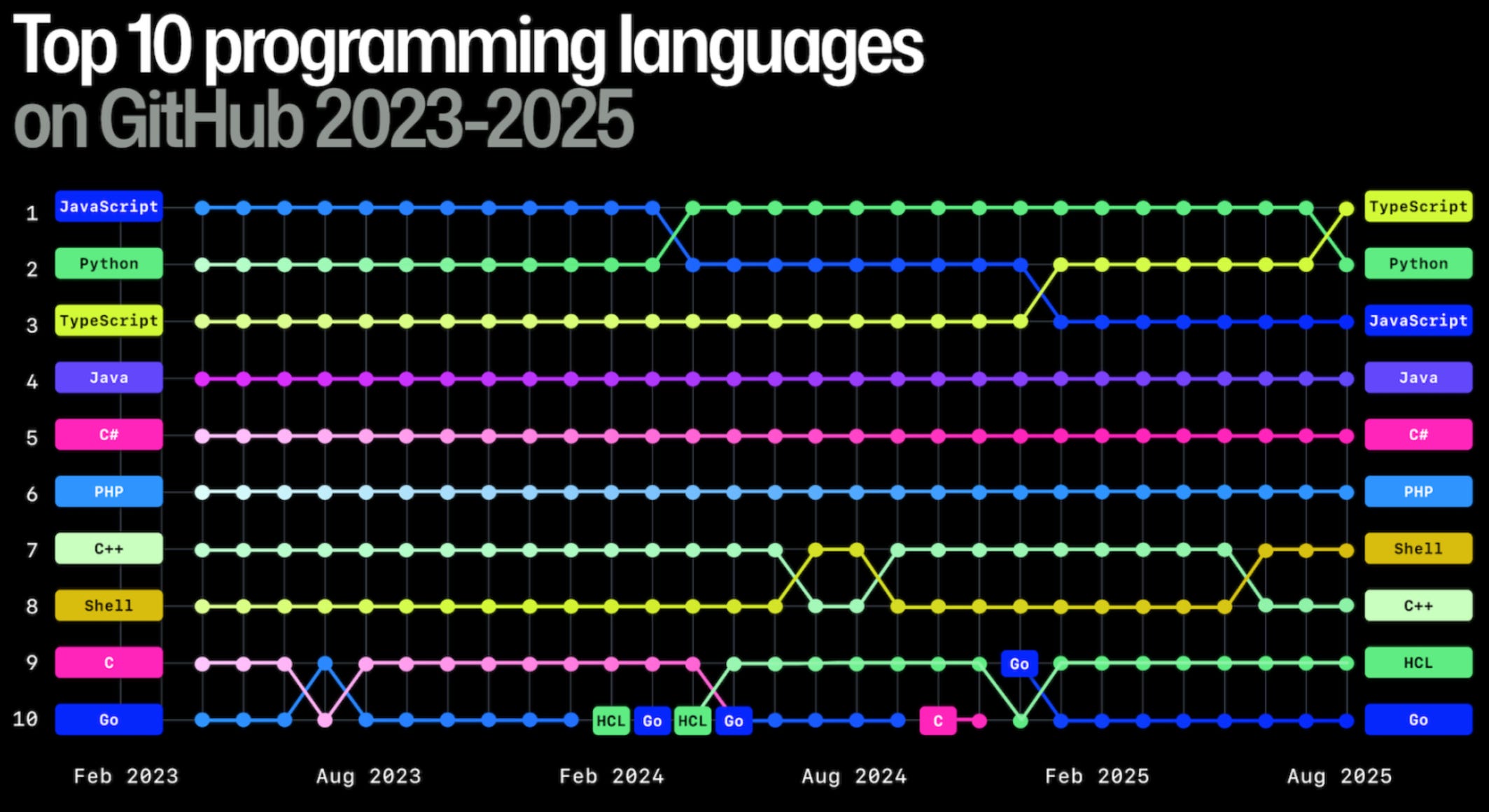
Every year Github releases a “state of the union” report highlighting the biggest changes or trends and this year’s had both expected (AI growth) and unexpected (Typescript #1 most used language) news.
The full report can be found here, but here some the most interesting numbers to me:
Number of average pull requests and commits grew ~25% YoY
Even if fuelled by AI code generation, these numbers are impressive as just the number of commits reached almost 1 Billion in 2025.
LLM SDKs being ever more common with 178% growth YoY
It is not just developers relying on AI assisted tools for code generation, is projects actively using AI as part of their operation.
Typescript overtook Python as most used language in GitHub
That was surprising as Python was the dominant one, largely due to the increase in popularity of data science and AI workloads of recent years. The fact you can run Typescript as a true full stack language, fuelling the UIs and the server needs, plus the maturity of the tooling involved are likely to be part of the explanation.
Private x public contributions ratio is ~4.4
This means that majority of the contributions happened to private repositories, despite the fact that public repositories represent 63% of the total. So the number/volume is way higher to the closed-source ecosystem while depending on the libraries, frameworks and tools provided by open-source.
Brazil and India had a 5-year CAGR of ~34.3%
In the top developer popularity be country both India and Brazil gained 1 spot, accounting to #2 and #4 positions. India surpassed China and Brazil surpassed the United Kingdom.
While the United States still sits in #1, if this rate continues it could be overtaken by India in a couple of years. The surprise here is Brazil x China, where the number of developers per capita of Brazil can also mean #3 is not far away.
Object-Oriented Programming
Know why you don’t like OOP
Object-Oriented Programming has been with us for a while and is always among the most heated debates I witnessed, well that and tabs x spaces…
As someone who was introduced to it soon after working with C, the encapsulation and domain modelling selling points drew my attention. But if you look at what has happened for a while we see the strong types x no types, procedural x oop discussion coming often.
I have been leaning toward a mix of functional and OOP whenever I can, at least with my Typescript-based projects.
I guess a lot of the hate has come from the fact OOP has been forced on many, and never had the time, or interest of digging further and get to the real reason or meaning of its benefits. It is a classic process x outcome case.
This article mentions some of the parts that you can relate. I added my twist to each :)
Interfaces are fine, but overused and misunderstood
I started with the famous ISomething pattern just to have a single implementation with the exact name, or worse with the Impl suffix appended to it

The focus, which starts from the naming, should be intent and being able to provide you with the option of deferring the technology decision, and its implementation.
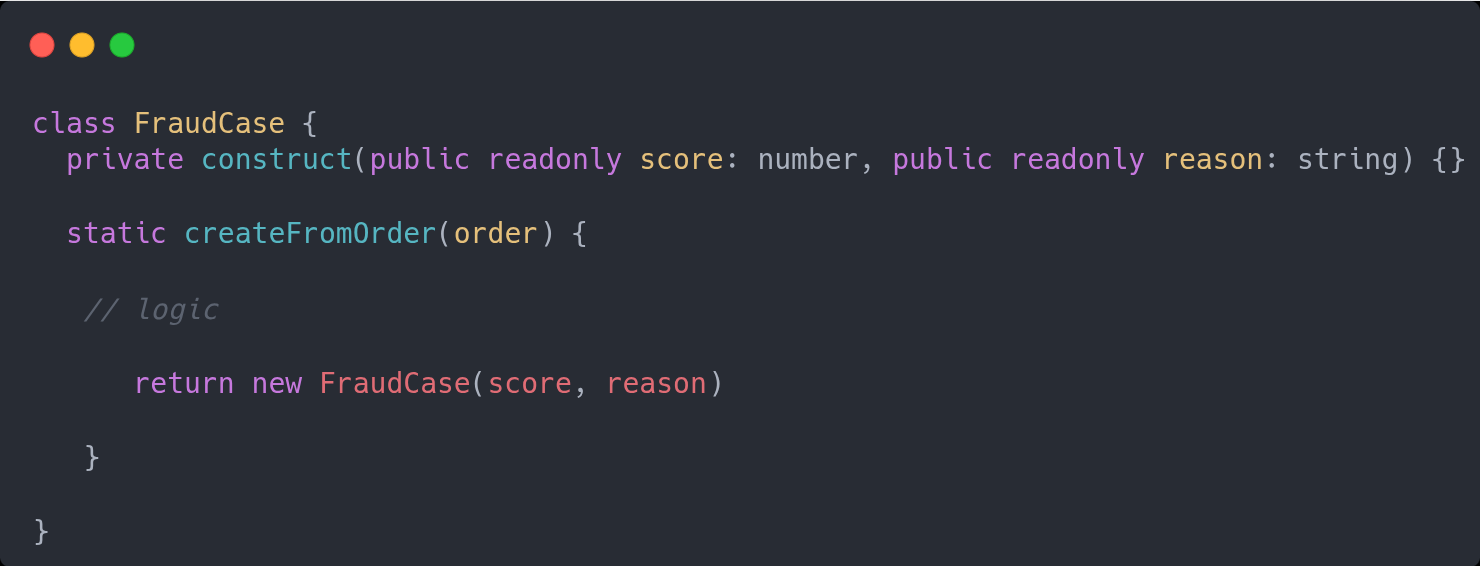
I try to focus on finer granularity first, so Refundable interface instead of a PaymentService option. Also, for the implementation focus on what makes this implementation specific. Is it a technology, a provider etc. So a Stripe implements Refundable may be more revealing about it.
Encapsulation is fine, but be careful with the “Service” approach
If the idea of methods are to provide some capability, encapsulating the data it uses, avoid the anemic model approach where you have a Something entity with just the data and a SomethingService with all the methods.
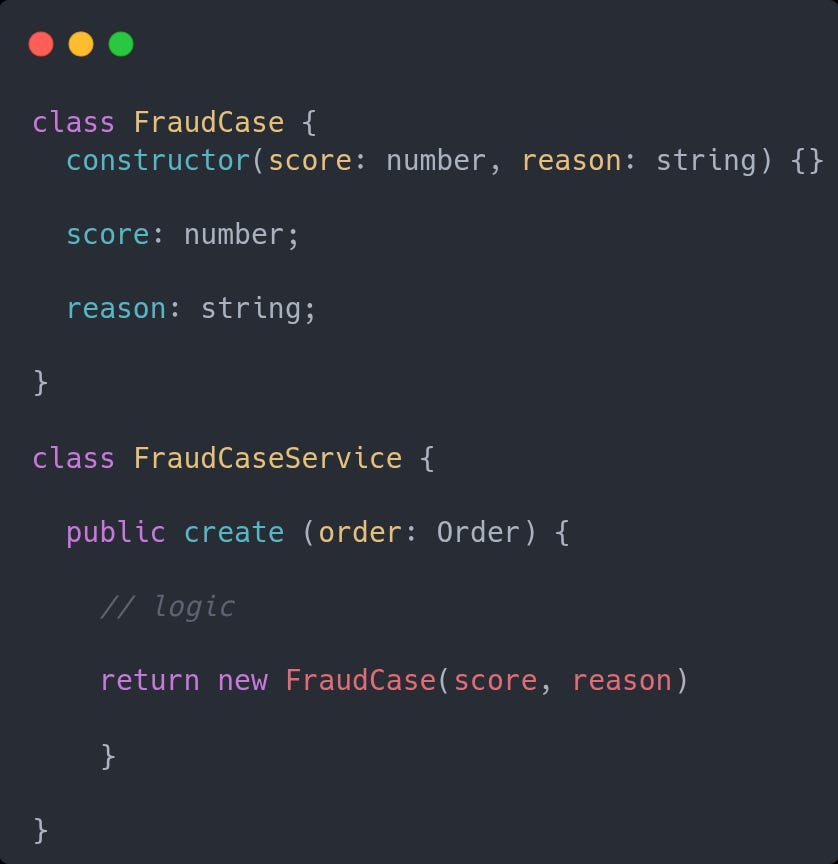
Instead, why not use this
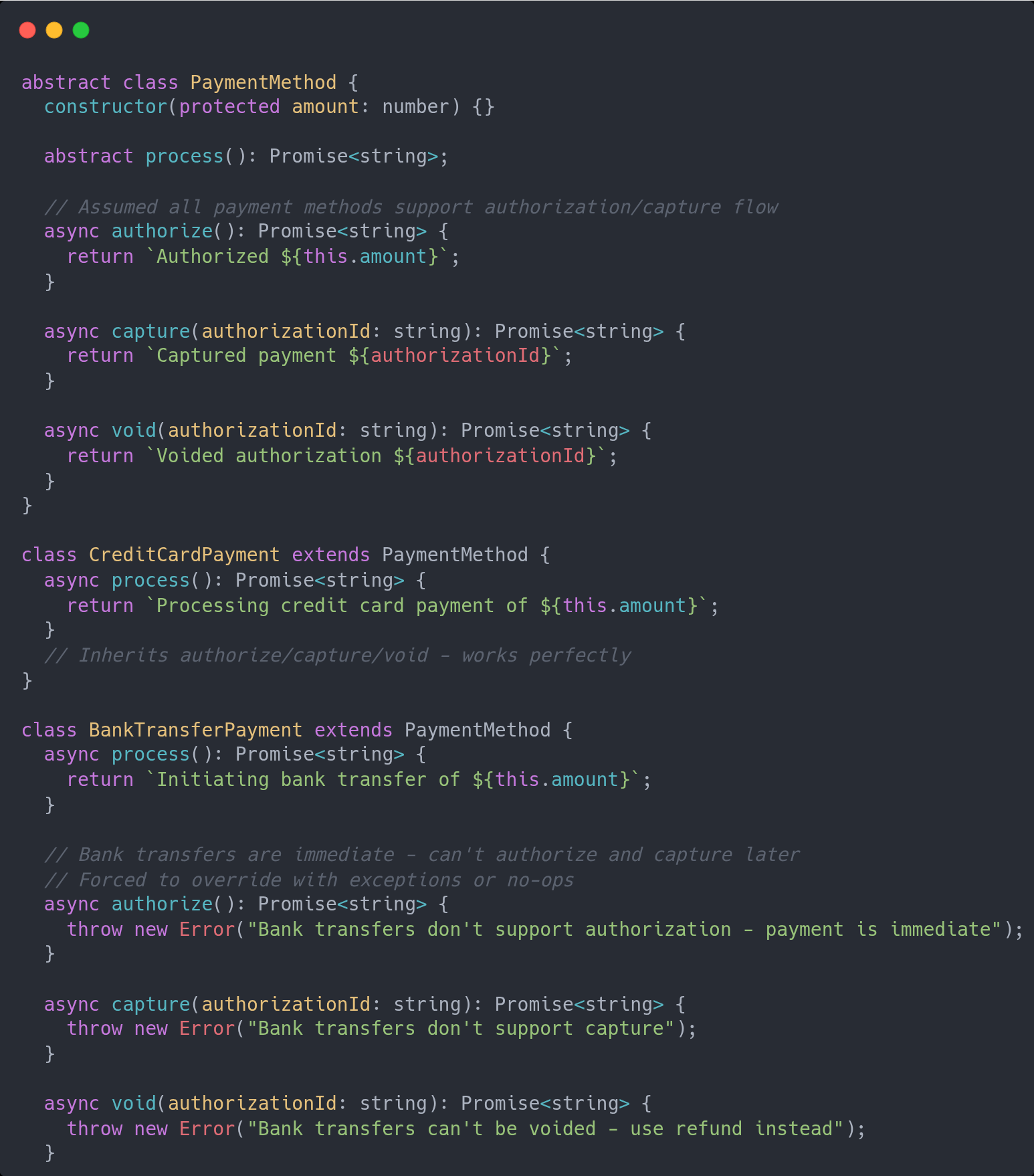
Inheritance is often bad
I blame this to the Animal, Dog and Cat class trees used in many OOP tutorials. Inheritance is powerful and really has its place but it is a trigger often pulled too quickly.
You just started working in a new domain, or feature, and all the sudden this is a type of that, let’s create a base class. Then you find out that your sub-class shouldn’t have the same behavior and you end up with some no-op method or additional branching logic.
Instead, we shift to composition.
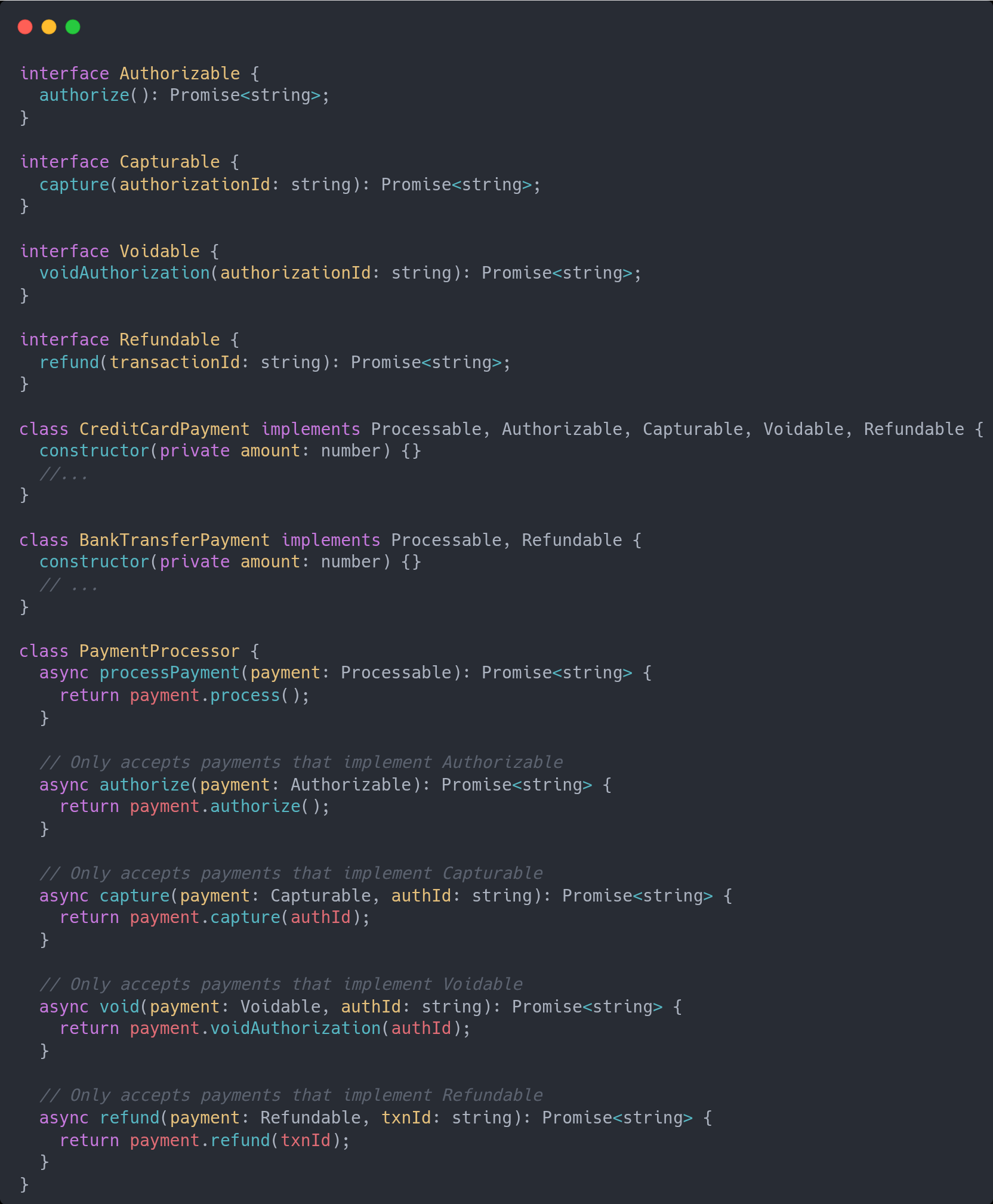
The PaymentProcessor receives an instance according to the operation that it is expected to execute. No more NO-OP methods due to a forced inheritance tree.
At the end, OOP on its own is neither good nor bad. The context of the problem you need to solve and how you use it will dictate how much it is helping or just being an overhead.