Serverless Generative AI Architectural Patterns
Supply chain attacks, refactoring infrastructure as code (CDK) and choosing IDs

Most discussions on AI and software development tend to focus on the benefits, how to achieve productivity gains, and some of the dangers, such as security, of adopting LLMs.
However, there is another important aspect: when your application uses LLMs as part of delivering its functionality. Recently, a two-part series of articles (Part 1, Part 2) from AWS provided some additional insight for anyone looking at architectural patterns for AI and serverless.
The first principle is the separation of concerns by dividing the application stack into three components: frontend, middleware, and backend layers, with the benefits being isolation and enabling scalability for each independently.
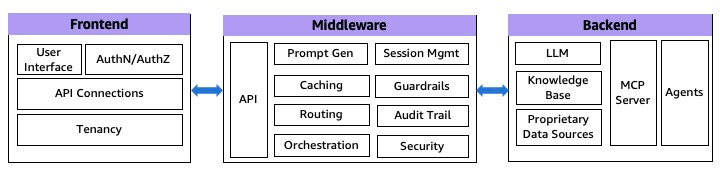
The frontend layer offers the interface between the user and the gen AI application, including UX, authentication/authorization, and separation between tenants.
The middleware hosts key components, from the API gateway to the prompt engineering layer, to prevent abuses (via guardrails), cost control (caching), and orchestration (agents, tools)
The backend offers the core GenAI capabilities: your models and knowledge bases used for RAG.
With that structure set, there are 3 patterns for the interaction
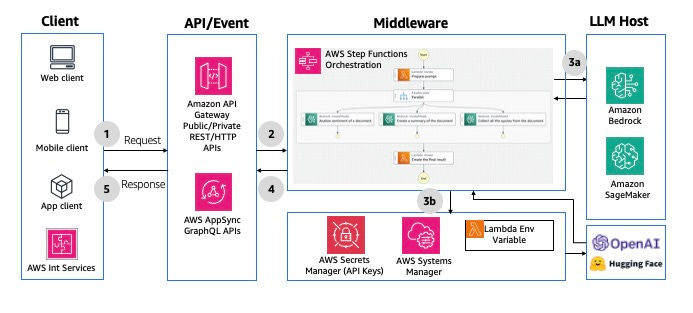
- Synchronous Request/Response
Responses are generated immediately and sent back while the user is waiting - blocking mode. You can leverage both REST or GraphQL HTTP APIs. A nice mention is the use of step functions to perform orchestration in the middleware if it needs to perform a complex chaining of dependencies.
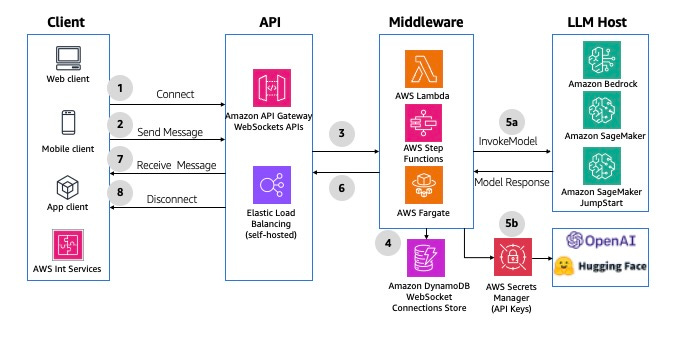
- Asynchronous Request/Response
Here, responses can be generated in a delayed fashion or if it is a lengthy process where the user relies on WebSockets to receive the response after they have been fully generated.
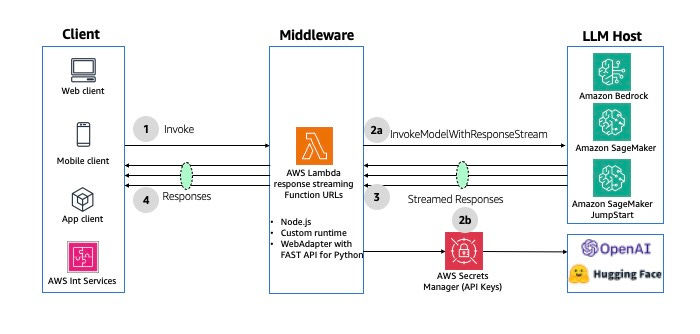
- Asynchronous Streaming Response
This pattern uses the streaming capability with WebSockets to support the case where the answer can be broken into chunks and sent back as it gets generated, instead of having to wait until the end.
All the above patterns are suitable when you need near-real-time or interactive applications. When you need to process bigger volumes of data, when a higher precision is required, or to react to an event, there are better patterns.
- Buffered Asynchronous Request/Response
The idea is to leverage event-driven architecture to improve the reliability and potentially cost by grouping events instead of processing them one-by-one as they arrive. A traditional polling can take place, like the one below
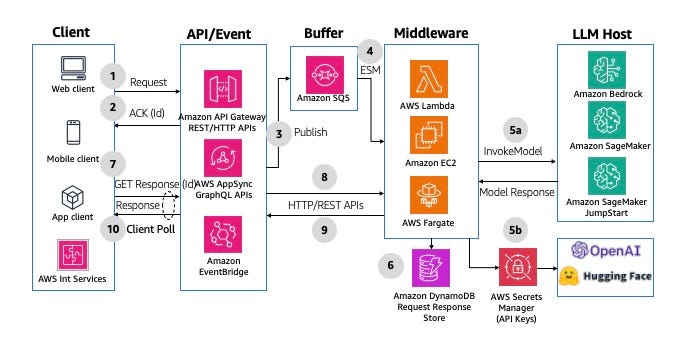
Or a WebSocket version.
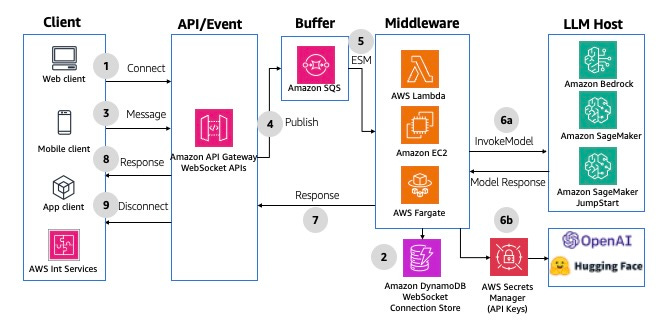
- Multimodal Parallel Fan-Out
A variation of the buffered asynchronous pattern where we use Fan-out (like pub-sub/message bus) to trigger multiple interactions that are combined before sending the response back.
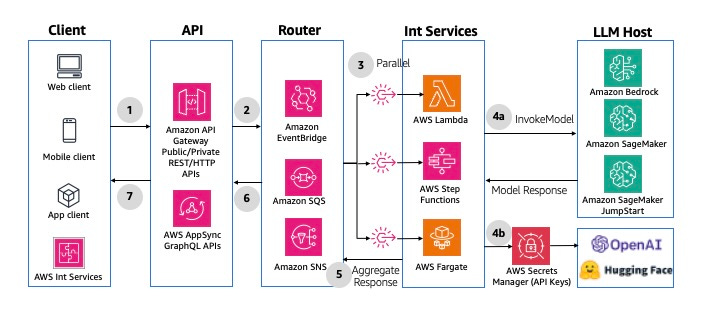
- Non-interactive Batch Processing
This is used when you have to process large volumes of data without the user interaction. For example, if you need to update a forecasting model based on a recent time window of data.
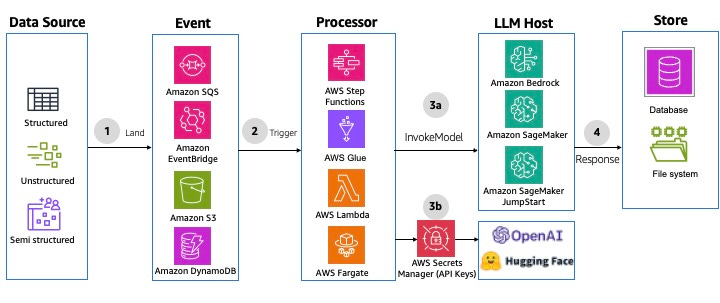
The bonus is that you can apply these 6 patterns in other cloud providers as well, replacing the components with their counterparts.
Development
Designing APIs for Humans-Object IDs

Data persistence is something that most services can’t escape, and with that comes the inevitable choice of how to represent the identity of the entities we manipulate.
The traditional approach, coming from relational databases, relies on auto-increment numbers that are generated when records are written. Those, while simple, suffer from two major issues: they are difficult to guarantee uniqueness when you need to scale to more than one write database, and they can be prone to enumeration attacks.
The second most common choice is UUID, which has a very low chance of collisions — making it suitable for distributed generation — and equally hard to guess. There are, however, three downsides:
a) It is not user-friendly (try reading it over the phone)
b) It is not particularly meaningful “01998bd4-1c39-7165-9637-a1b61909c4ad” :)
c) Some UUID versions lead to suboptimal indexing.
UUIDv7 solves the last issue, but the other ones remain.
At Stripe, they opted for a different approach by having a prefix that has some business meaning.
pi_3LKQhvGUcADgqoEM3bh6pslE
└─┘└──────────────────────┘
└─ Prefix └─ Randomly generated characters
Doing so allows developers and support staff to quickly understand what the ID is supposed to represent.
It can also be used to prevent errors! Imagine you want to prevent users from using production keys in testing environments.
If your identifiers have this context, you could generate the test below
if (preg_match(”/sk_live/i”, $_ENV[”STRIPE_SECRET_API_KEY”])) {
echo “Live key detected! Aborting!”;
return;
}
echo “Proceeding in test mode”;
And add it to your CI/CD pipeline.
One of the biggest struggles seems to be when you need to integrate with legacy systems that still rely on the autoincrement style, forcing you to add a proxy ID to match 1:1 the internal ID with the external one.
Cloud
AWS CDK Launches Refactor Support
Infrastructure as Code (IaC) was a big improvement, helping to create reproducible environments quicker and more precisely than before, when manual steps and custom scripts were the norm.
There are several approaches and one that takes the “As Code” to the limit is CDK. With it you literally create applications, stacks and constructs — like queues, lambdas, DynamoDB tables, etc — using a programming language such as Typescript/Python/Java. There are some advantages when comparing to other solutions like CloudFormation, including the possibility of create composable components (stacks, constructs) that enforce governance or technical decisions from your company.
One of the limitation of CDK was the fact that if you renamed constructs or needed to move them between stacks. Those usually lead to the “old” resources being deleted just to be recreated with new logical IDs. For stateless resources like lambdas this impact can be small, but with resources like queues, databases this can lead to downtime and data loss.
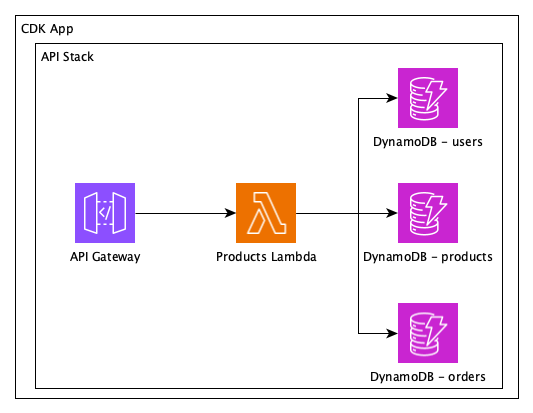
or example, if we were to refactor the previous application to separate the monolithic lambda into separate ones and different stacks per area, we would end up with the solution below.
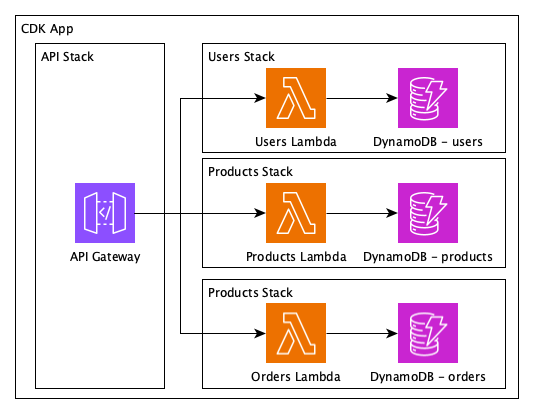
The new solution is better but to get there we would however delete and recreate the DynamoDB tables. CDK now offers a refactor capability that detects the changes between the current version (monolith) and the new state (separated).
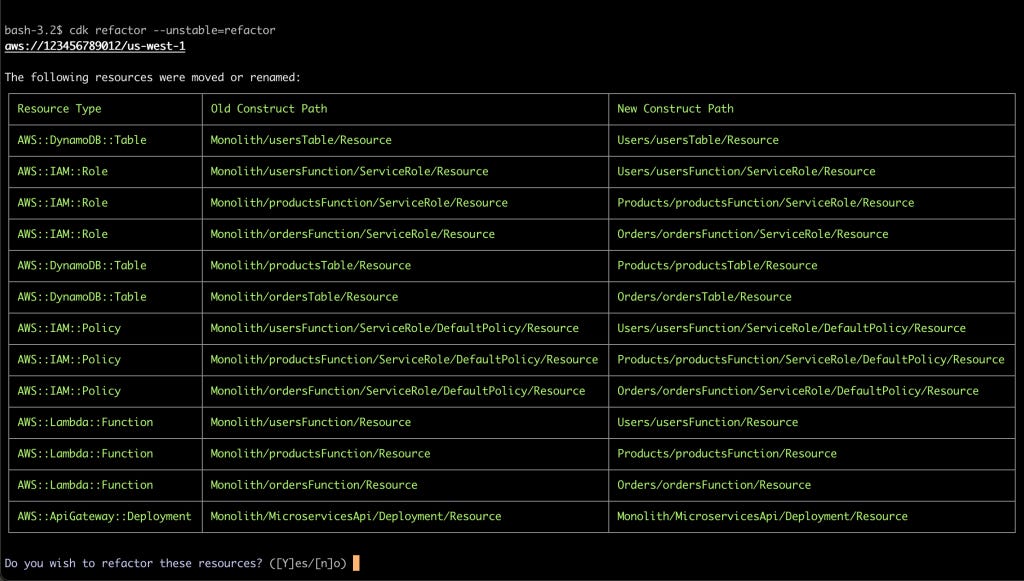
If you choose to proceed, it will make the change without the downsides we had previously.
This is a nice addition that helps you evolve your application with more confidence and without having to resort to hacks to get you to a cleaner state.
Security
Supply Chain Attacks

Today, it is common to depend on many open source packages as part of our applications. Most languages offer some sort of central registry where you can publish your contributions.
While this facilitates enormously the job of developers looking for what package may exist to address your needs, it also enables a form of attack many disregard: the supply chain.
Most of us, when we think about security for our applications, we think about the layers of protection, from firewalls, certificates, keys to leveraging techniques as filtering in the code we develop. But how about the one we “adopt” from others?
In September of 2025, there was a series of attacks that did not target applications directly. Instead, they went after widely used npm packages, leading to at least 18 being compromised.
Just as an indication of the reach of these attacks, combined, all the compromised packages represent 2.6 billion downloads per week!
This is nothing but a reminder that we should be careful with these external participants as well, ideally restricting the number of those we rely on.
Additionally, the use of static analysis tools as part of your CI process will serve as another way to catch these issues before they reach production.
If you want more in-depth articles about software development and architecture, check my blog.
It's always such a pleasure to read your articles, Mario. You explain the API and ID generation topics with such simple elegance.