Specification-Driven Development
Kiro - The New Kid on The Block

When you thought the IDE space was already crowded, AWS released a new Visual Studio Code fork named Kiro.
While still in preview, what seems like a promising start is its focus on establishing a workflow based on the notion of an evolving specification.
Seems familiar? Other IDEs, such as Cursor and Windsurf, have been incorporating the task breakdown concept as a means to break down complex tasks into smaller increments, thereby preventing the LLM from straying too far from the original request.
Kiro turns the volume know up and, as you work, it creates and maintains a list of requirements, a technical design document, and a task breakdown.
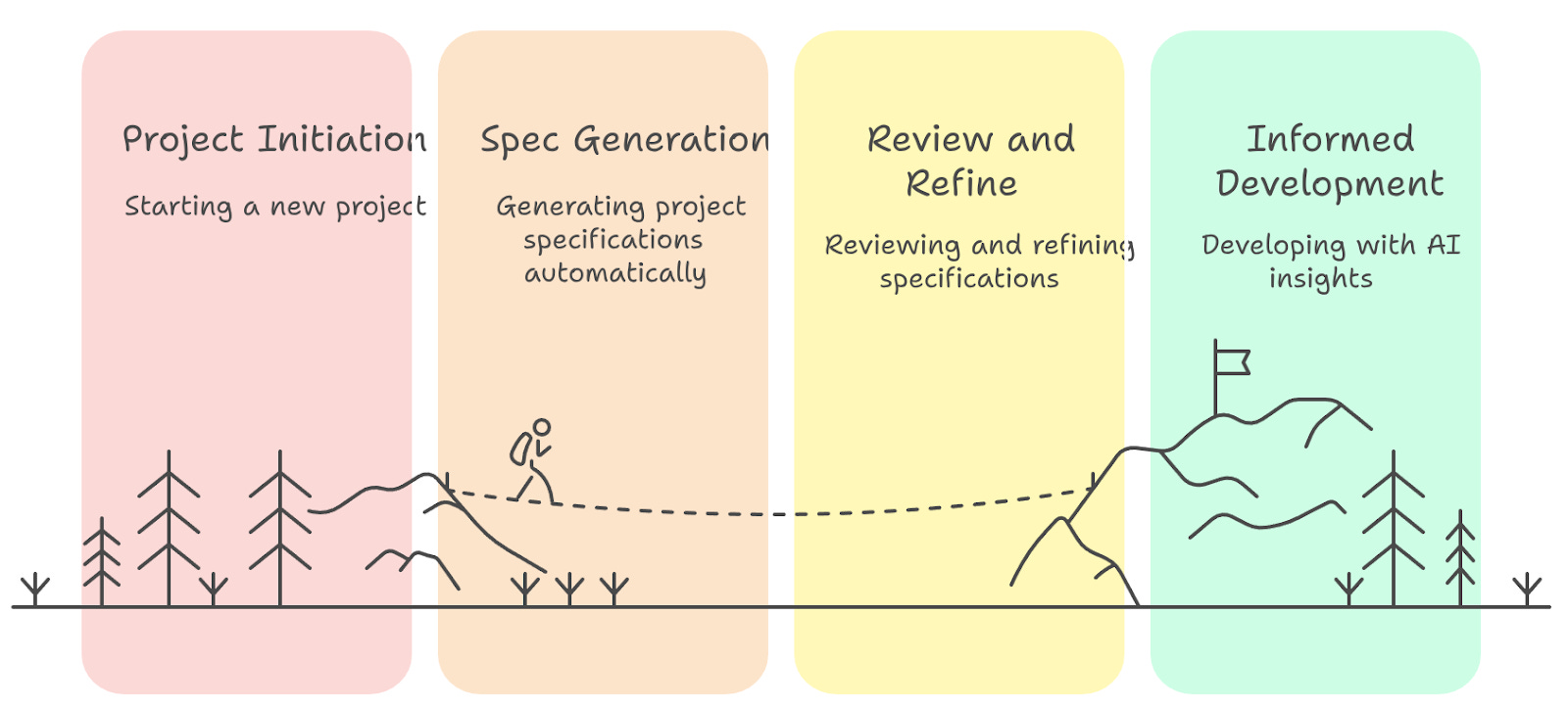
What makes me happy about this new option is that it takes a sustainable approach, keeping the developer closer to the important aspects: focusing on the requirements, having a design document to guide decisions, and having an implementation plan.
I would not be surprised if this could even serve as a coaching practice for young developers or those lacking the habit of producing those artifacts as the development evolves.
The fact that it comes from AWS, known for having a strong stance on formal requirements, hopefully inspires the other IDEs to follow suit and adopt the parts that make sense for them.
Like Marc Brooker mentioned, “Kiro’s specification approach is an important and powerful step towards a future of programming where outcomes matter more than implementation details.”
Being a Visual Studio Code fork also suggests leveraging a plethora of already existing extensions, reducing the entry barrier for anyone using the other options out there.
AI
Why Your AI Coding Assistant Keeps Doing It Wrong, and How To Fix It
The ongoing discussion in the AI-assisted development case tends to focus on whether AI can produce high-quality code.
We have a fair share of developers on both sides of this, but as this article suggests, we should focus more on finding which coding tasks it can be good at and which ones it currently is not.
When looking closely, our AI developer companion shares conflicting attributes:
Can write code at the level of a solid senior engineer, but is prone to make decisions at a junior level, as it rarely challenges requirements or suggests alternatives
Is knowledgeable about a variety of languages, frameworks, but knows little to nothing about our codebase, practices
Seems to be eager to impress, doing more than what is needed, but tends to focus on the problem directly in front of it, without proactively trying to improve the design
Using those attributes, the following constraint-content matrix can be created to help answer the what to do/what to avoid
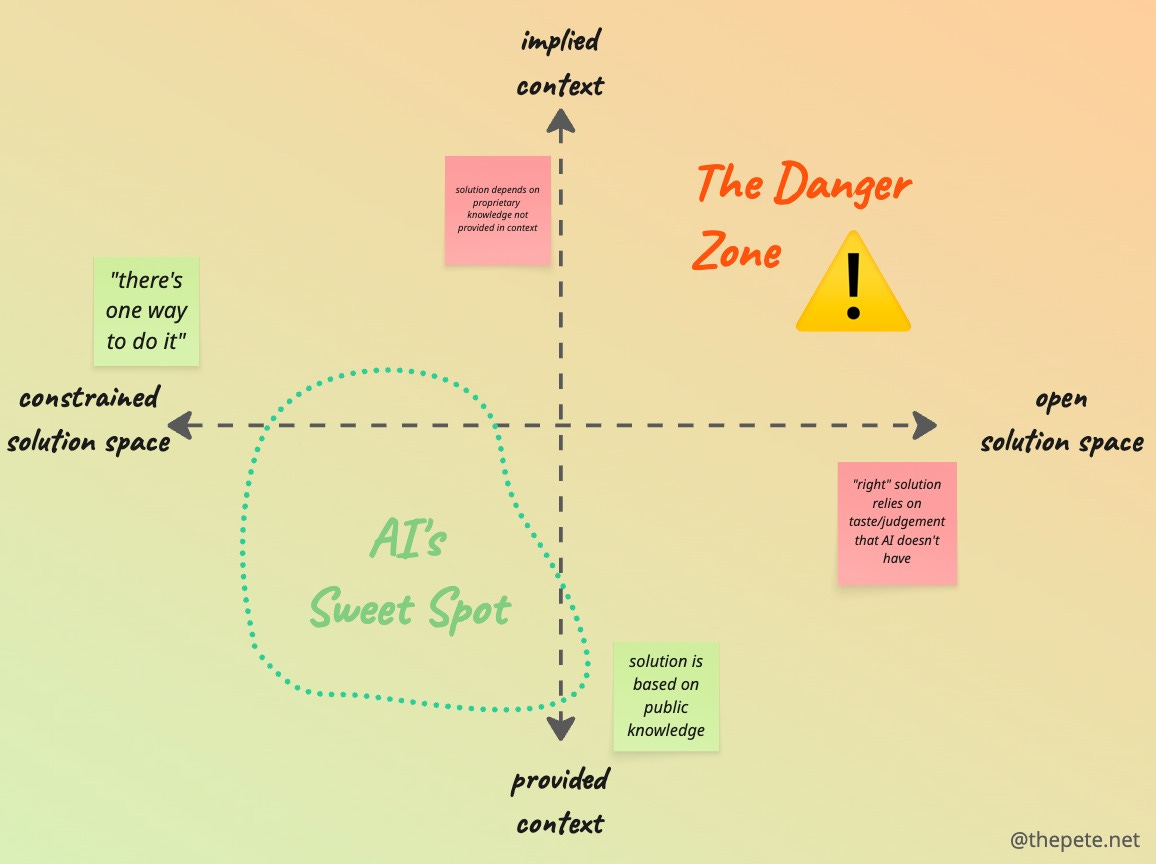
You can see that the more open the solution space, the higher the chances AI will provide a solution that will fall short of your expectations. The same goes when the information (aka context) needed is proprietary and not explicitly provided as part of your request.
Unsurprisingly, if we find a way to constrain the solution space and provide proprietary information as part of the context, you can increase the usefulness that you can obtain from AI.
Be more directive, break the problem down, provide coding standards/preferred libraries/architectural principles, and expand the prompt with the details.
Performance
Tail Latency Might Matter More Than You Think
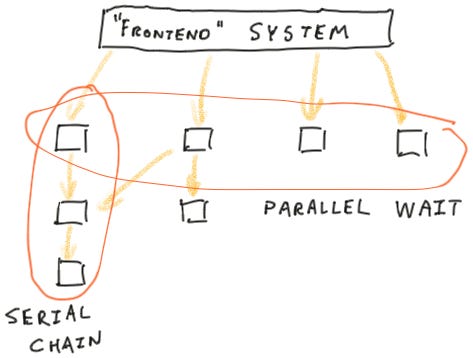
When talking about the performance of your system or service, it is common to refer to the PXX percentile, with P90, P95, or P99 being used to determine what is normal. The logic seems to be that if my P99 is 10ms, then only 1% would fall outside this and therefore be rare enough to not be of concern.
This so-called tail latency can, however, creep up as the number of services involved increases. As seen in this article, if you have services being called in parallel, then the response time is the slowest of them all. If the tail latency manifests, for a single service in 1% of the cases, then you will end up having the worst case around 10% of the time.
If the service call involves a serial chain of calls, things escalate even quicker, making the unlikely scenario closer to a norm than an exception.
The takeaway for me is two-fold:
If it makes sense, consider delegating certain aspects to an asynchronous flow. If you reduce the number of active dependencies, you have fewer contributors to the tail latency
Make sure to include end-to-end monitors on your latencies, especially for critical use cases
Coding
Refactoring: This Class is Too Large
Refactor is a word used way too often, frequently applied to describe an actual rewrite or executed in a “big bang” style.
Martin Fowler’s Refactor book identifies several patterns that you can use to classify and perform the actual refactor progressively and safely.
However, I see many disregarding that as it sounds too academic, as if it only applies when we are looking for perfection with those crafted examples that fit perfectly to the narrative.
It is a common struggle to transpose what we studied to the real world. This is one of the reasons the article “This class is too large” is interesting.
It tries to apply some of the practices of true refactoring, while keeping it real. The reminder of “why” a refactor is one of the starting points for a situation like that.
Ultimately, moving the code will serve to create clear contexts around the code, enabling you (and your team) to more easily know where you should make a change, reduce the working surface, which in turn can make it easier to avoid unwanted side effects.
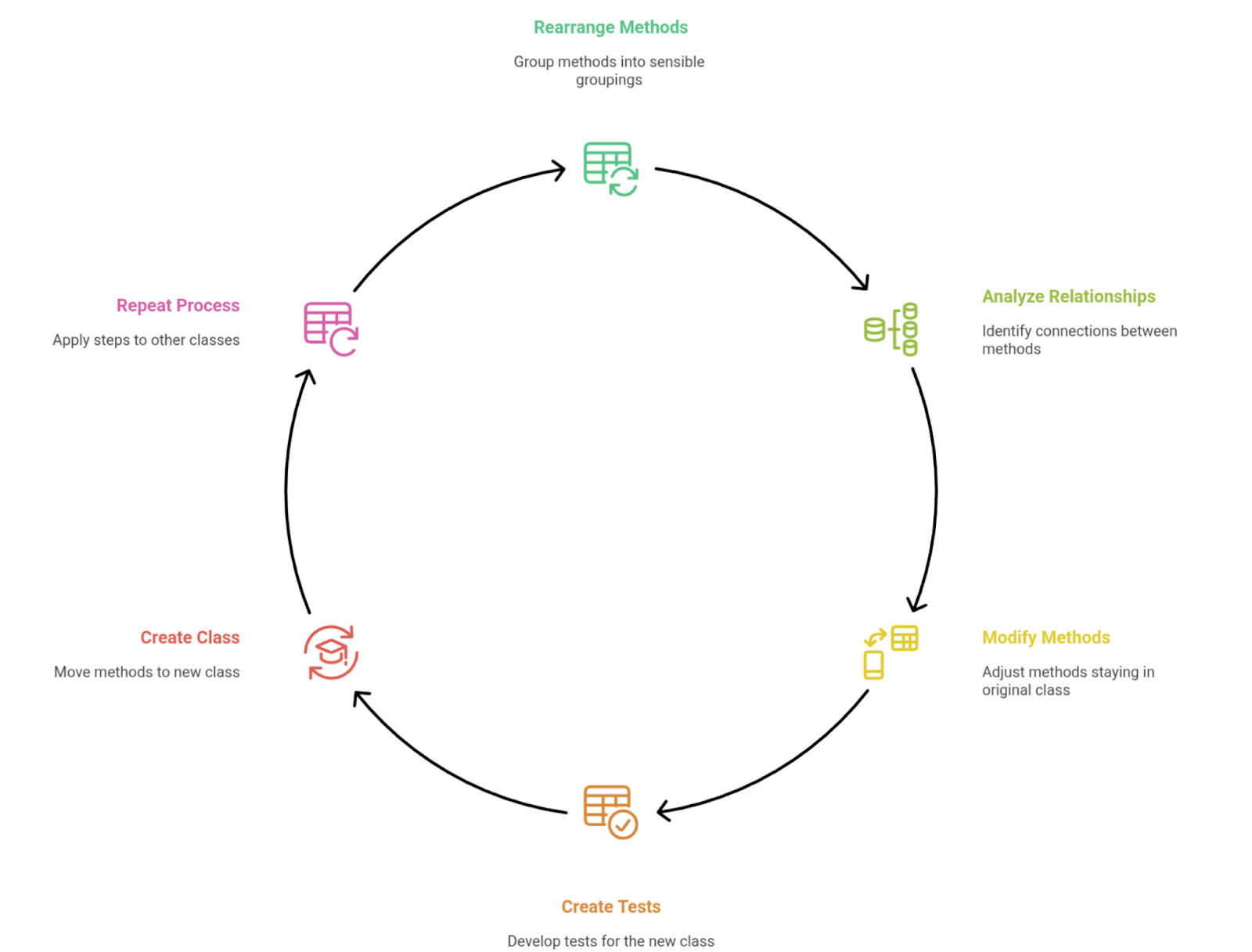
The process outlined is:
Rearrange methods
Group all the methods in the class into sensible groupings
Analyse the relationships between the methods you want to extract
Take one grouping and identify how its code is connected to the rest of the code in the original class
Modify the methods that are staying behind
Some methods will stay in the original class but are currently called by those that are moving. Some modifications will be required to make this work.
Create covering tests for the new class
The new class needs to be covered by tests. The tests for the code to be moved already exist, but they'll be moved into a new class. This follows a bit of the TDD principle here of adding the tests first.
Create a new class and move the methods
Following the principle of tiny steps, move some of the methods first. As it continues to pass the tests continue to move the other methods.
Repeat the process for the other classes.
When refactoring the code, be sure to resist the temptation of updating the behavior of the code and the structure (moving to other classes, changing signatures) at the same time! If you do, you will end up with two probable causes of issues, making your job unnecessarily harder.
Meta-analysis of three different notions of software complexity
Software development has never been an easy industry. It seems like a living example of the Jevons Paradox, as new technological improvements increase efficiency, we find ways to increase the consumption/complexity.
Accidental or not, how can we define complexity? This article offers a short discussion on the definitions provided by Rich Hickey, John Ousterhout, and Zach Tellman.
The idea that “complexity is caused by two things: dependencies and obscurity” is really powerful and should be one always in your radar. Keeping the number of dependencies under control and focusing on the clarity of intent (no SomethingUtils, SomethingData, SomethingInformation classes/properties please) is a good start.
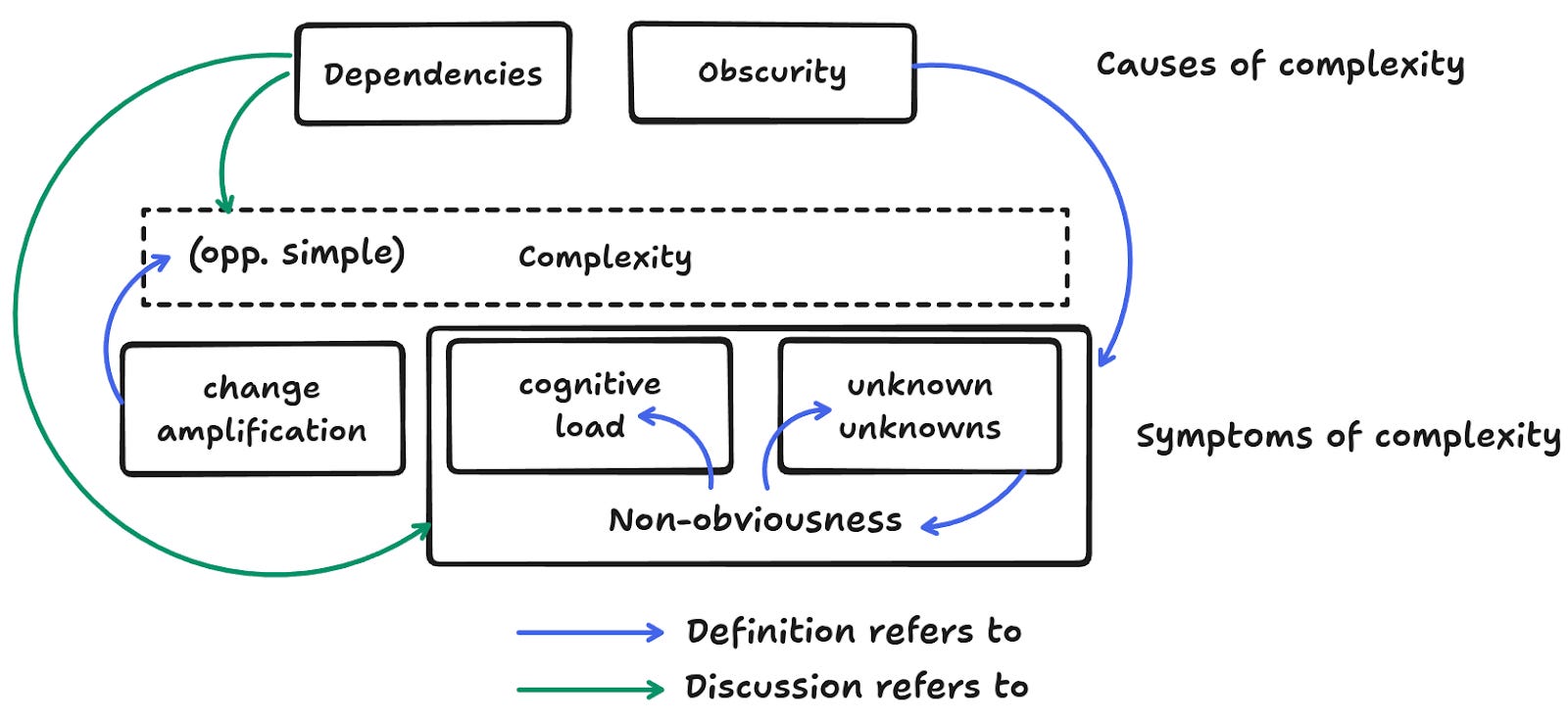
Another definition of complexity comes as the amount of explanation you have to give for newcomers. It takes into account the fact that familiarity changes the perception, but the more you have to explain about your software, the more complex it still is.
Leadership
5 things I learned from 5 years at Vercel (well, not me me, but you get the picture)
Even though it is said that bad news sells more than anything else, social media is all about the successes of individuals/companies closer to our jobs/hobbies/interests. The routine of X and how they achieved success by waking up at 4:00 am and wearing the same shirt every day…
When looking at non-technical aspects that can help me improve, I am more interested in what others may have experienced and learned, so I can draw parallels with my reality and tweak things a bit. In that sense, I came across this article from Lee Robinson reflecting on his 5 years at Vercel.
Go hard at work, then go home - It is all about establishing boundaries that allow you to still be passionate about things at work while knowing when to “go home”, which to me translates to disconnect and focus on the other aspects of your life. A reminder for us all, and more importantly for anyone with a leadership (title or not) position: be careful not to steal ownership from your team members!
Everything can be done faster - Establishing the pace is part of your job. As a leader, if it is ok with you that things move slowly, they will. It all starts with understanding what is needed to move faster and providing the right support for that. That to me has two components, the almost now cliché continuous improvement, and having a positive stance on the pace. Unfortunately, the latter is something that I find rare, with most developers taking a stance of “this is the time it takes” without even entertaining a more conciliatory position and proposing “If we remove this part, we can deliver within X weeks”.
Scale or die trying - If business is booming, there will always be more things to do than the capacity, so the challenge as a leader is to handle the scaling demands. It means being able to take ownership of the things you have been assigned and making those around scale with you. That involves hiring the right people, making it clear that growth is expected, being an example, and supporting them in the journey.
Don´t swoop and poop - Leadership is more than the title you have, and gaining trust is not optional if you truly want to improve and scale, as it makes the team members also want to improve, change. It demands more energy, but listen to what they have to say first, (potentially) adjust your narrative, and then begin. Be humble, as your idea will not always be the best one :)
It’s ok to change your mind - The environment we operate is complex: new technologies appearing, new features, tighter deadlines, you name it. In this context, wanting to know everything so you can make the “right” decision is hardly the norm. The Amazon analogy of one-way vs two-way decisions is a reminder that it is ok to adjust the approach taken after more is learned. Learn how to differentiate such decisions, responsibly delegate those that are two-way to the team members, and avoid being a bottleneck.
Quote
A change should be structural or behavioural, but never both. - Terhorst-North
All opinions are my own.