What Loop Engineering Actually Requires
Homebrew 6.0 locks down supply-chain risk, and Azure HorizonDB's single write node might be its biggest tradeoff.

Loop Engineering
We truly are living through strange times. Not too long ago, we were talking about prompt engineering, context engineering, and just as I was about to write about harness engineering, I stumbled across the new kid in town: loop engineering. That is a lot of engineering in so little time :)
So, what is loop engineering? This article gives a simple intro on the topic, but the simplest way is to compare how the ancient ones used to work with the coding agents.
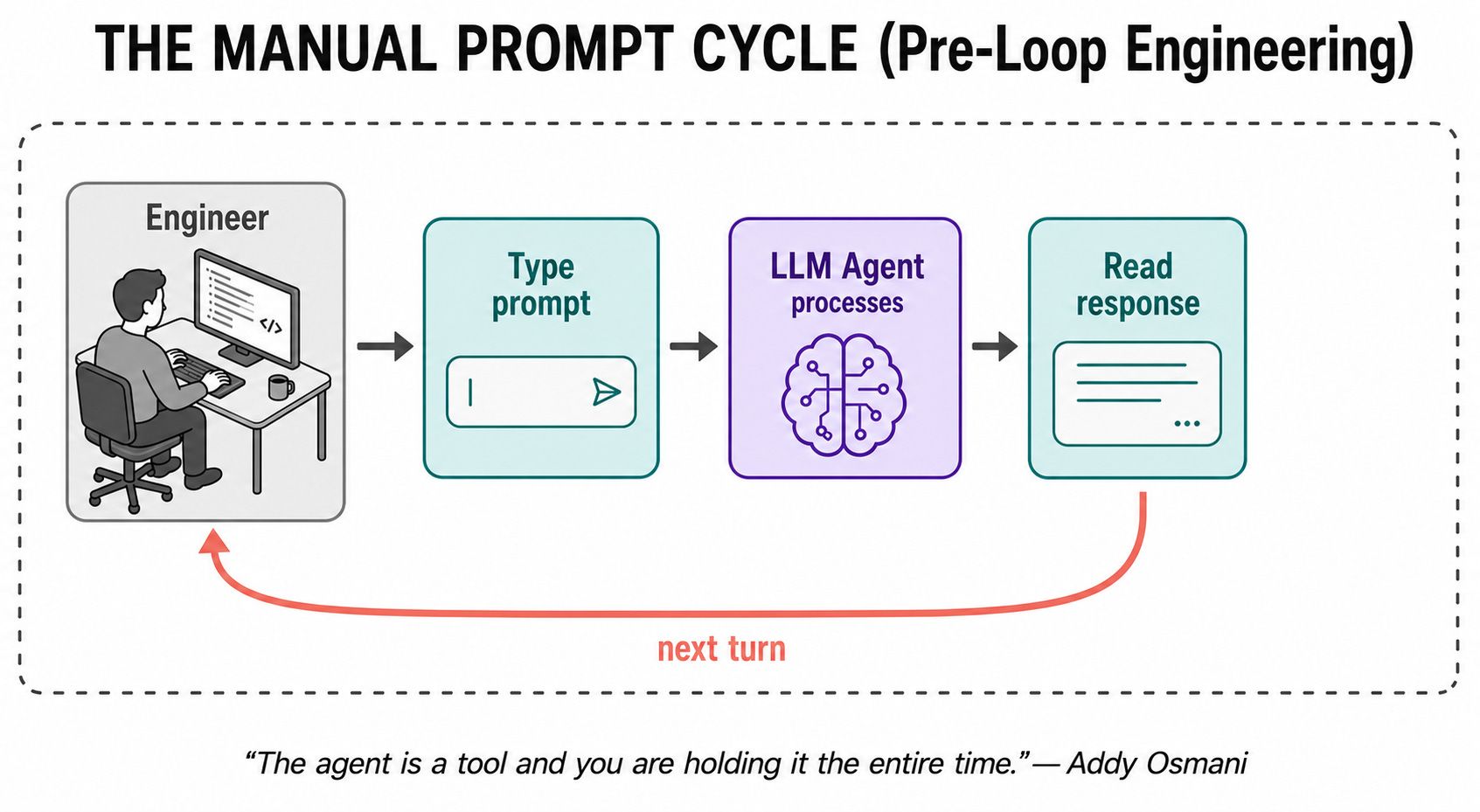
So, you provide the input, the LLM sends something back, you provide the next input, and the process repeats.
In the loop engineering, you build a small system that finds what needs to be done, provides this to the agent, checks the output, marks down what is done, and picks the next thing.
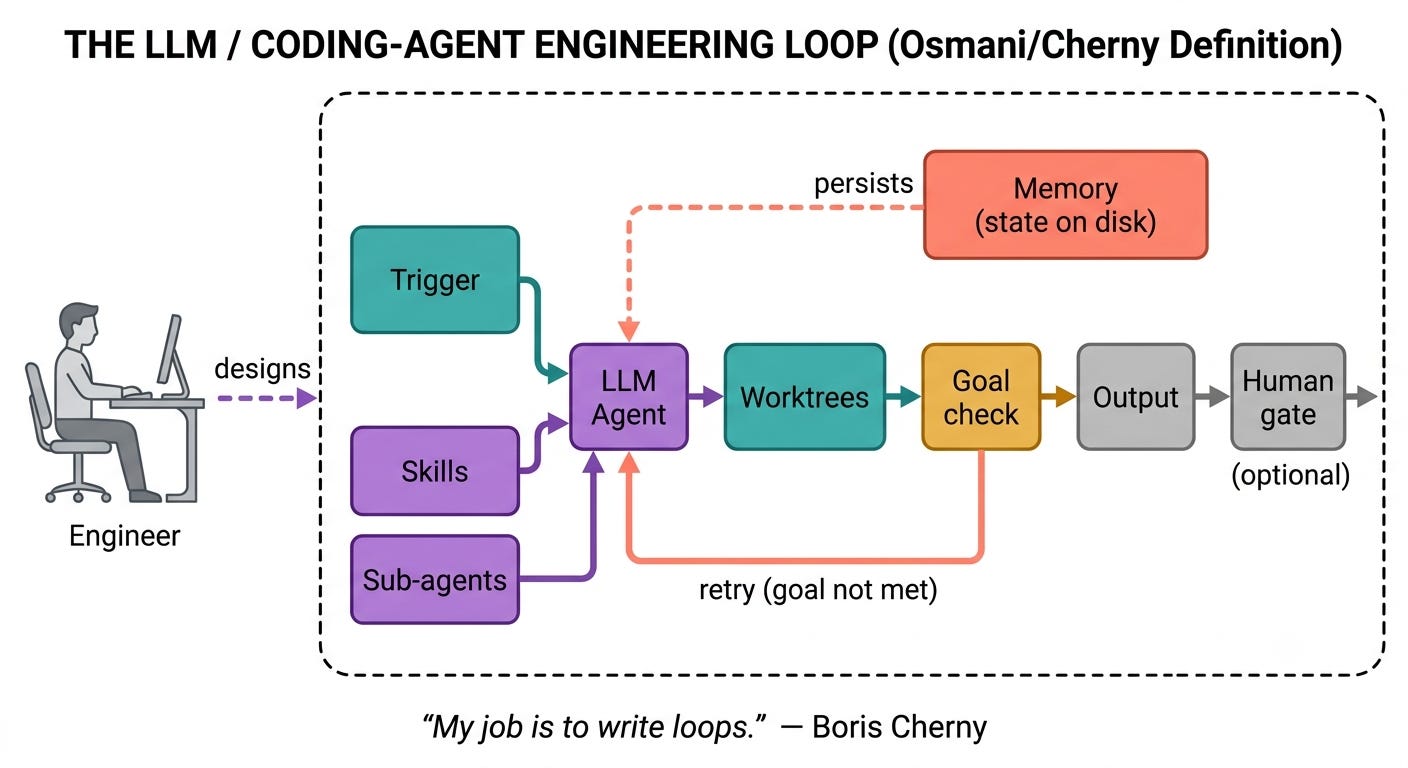
A loop needs 6 capabilities:
Automations that are executed on a schedule to locate new work (from a list that gets triaged)
Multiple concurrent versions of the same codebase, using worktrees, so 2 or more agents can work in parallel on the same code
Skills to capture the project’s knowledge
Plugins to connect the agent to the tools already in use (e.g Jira via MCP)
Sub-agents, so you can split the work between the one that executes and the one that checks the results.
Memory to hold what has been done and what is next
To me, the tricky parts are still the definition of what needs to be done, how it needs to be done, and setting up the environment that enables proper validation.
What needs to be done - it is a challenge for most, where the definitions are incomplete and ambiguous (lacking a proper and stable language).
How it needs to be done - your team/company coding standards and libraries are scattered or unevenly implemented across existing codebases.
Setting up the proper environment - local or remote, the DevEx is a tricky subject for most distributed/microservice solutions.
If those 3 aspects are not properly addressed, chances are you will be spending a lot of tokens and still end up in a different place than expected.
Homebrew 6.0
Linux users are used to installing and updating software via some form of CLI package manager (apt, dnf, yum, etc), and even Windows provides one in the form of winget.
For the Mac community, Homebrew is the usual choice, providing an easy way to have a similar experience.
With the latest 6.0 release, Homebrew added some interesting capabilities and improvements:
Tap Trust
Homebrew requires the tap to be explicitly trusted before allowing the execution of the Ruby code associated with it. This is a welcome feature, specially in these days where supply chain attacks seem to be common.
Improved Linux sandbox
Linux and macOS sandboxes are aligned, making the build, test, and postinstall phases hardened.
Faster
The startup is ~30% faster, parallel fetching on upgrade, and less work loading the Ruby libraries at startup.
Any developer on macOS should consider upgrading.
You can check the full announcement here.
Managed Postgres: Azure HorizonDB
Choosing a persistence technology is not an easy task, with many relational and non-relational options to choose from. One of the choices that has gained a lot of momentum has been Postgres that always presented itself as the most feature-rich option of the open source solutions.
It has expanded its traditional relational approach with the support of JSON, vector search, time-series, and graph queries, to name a few.
Microsoft has recently announced that it is offering a managed solution named HorizonDB.
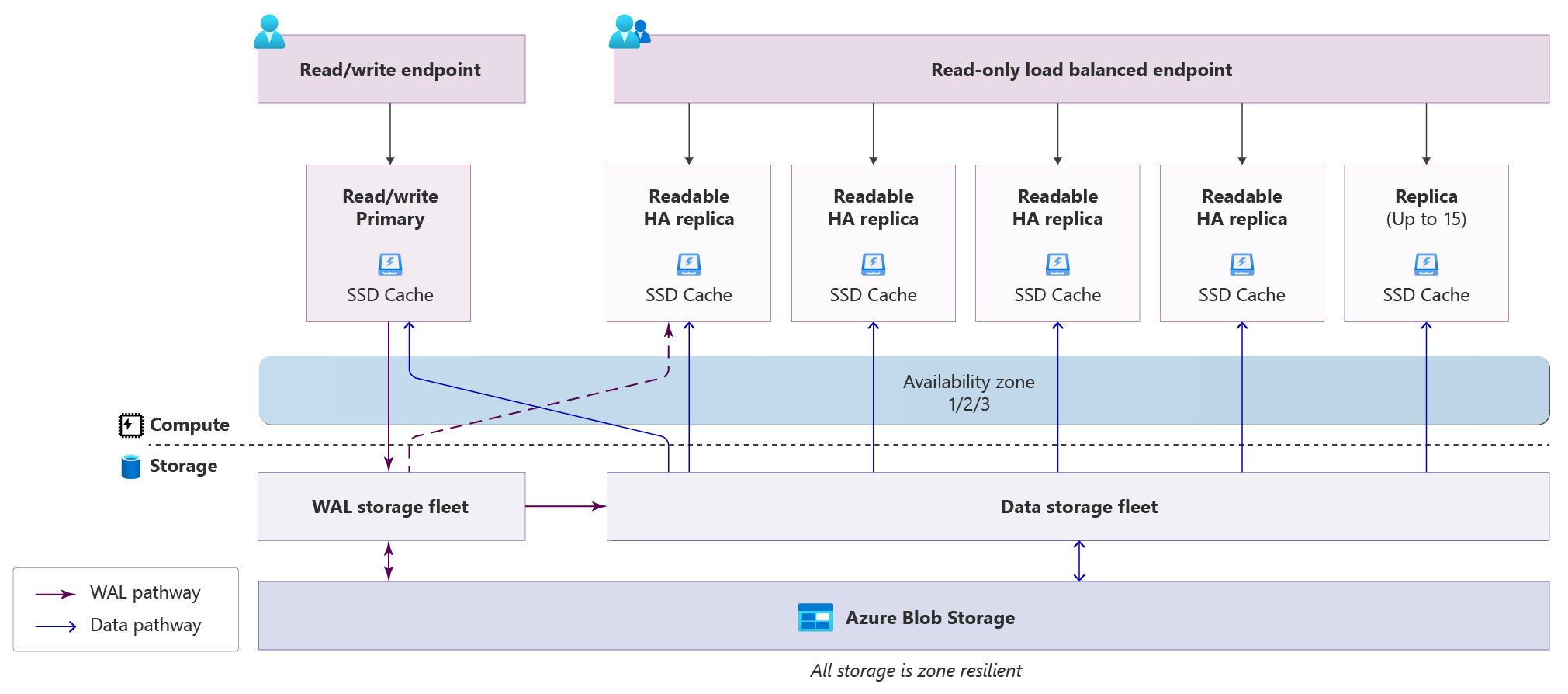
Some characteristics drew my attention:
It exposes two endpoints, a read/write and a read-only
Positive. You can point your application to the endpoint according to the nature of the operation.
Since the replication is still async, you have to direct reads to the write node if your application does not tolerate eventual consistency.
It has support for up to 15 read replicas
Positive. All replicas sit behind a single endpoint, so you can expand as needed, and the traffic is split across them.
It has a single write node
Negative. If your application is write-heavy, this node would have to be big ($$$) to support the traffic.
Each one of the read replicas is a candidate to be promoted to primary in case of failover
Positive. Good for planned or unplanned situations
Supports full text search, vector queries
Positive. Supports complex use cases
The offer is still in preview, so you can expect some changes until it reaches general availability.