The debt you didn't see coming
Understanding cognitive debt, reducing token usage for your agents and security paradox

Cognitive Debt

When you start using coding agents, it is not unusual that you start churning out a lot of code, fast. Assuming you are not vibe coding, this means that you feel responsible and care about the code it produces.
This article defines the cognitive debt that is associated with this, proposing that you quickly find yourself in a position where no one knows how it works. A shift from technical debt to cognitive debt.
While this can be true, I tend to agree more with another take on the subject that, as long as you are in control of the size and scope of the project, the debt AI introduces is not worse than when all code was human-generated. At worst, AI “helps” us to get to the same debt level faster if left unchecked.
Proposing and maintaining encapsulation is incredibly hard to achieve, and that only aggravates as the size & scope of the system grow. If you approach, as a newcomer, any sizable service that has been around for a while, you know how hard it can be to make sense of its components and layers of abstraction.
When properly used, AI can actually help you to find the current patterns used, challenge them, or propose alternative approaches. One of the areas AI can shine, and not often leveraged enough by developers, especially the seasoned ones, is refactoring.
If even good decisions from the past can age like fine milk when context changes, imagine ill-conceived ones! How many times have you been dissuaded from making changes due to the time it would take and/or making sure you made all the changes you needed to?
Now, the effort required to make these changes can be drastically reduced while you are still in control.
Describe the result you want to achieve, and the changes you want to make (which may or may not have come as the result of an AI-assisted code session itself)
Instruct it to make one change at a time, committing the code after the tests are back on green
You end up with smaller chunks of change to review, and know it only moved forward when the system is stable.
If you are doing more than refactoring, the same largely applies, but you have to account for compatibility to avoid breaking changes.
Save On Agent Token Costs with RFC-9457
When discussing the topic of AI usage with other colleagues, it seems we can have 3 main groups of companies:
- Not using a meaningful/consistent way
- Using frequently but with reservations or in a limited way
- Extensive / all in
For the latter group, token usage is likely already on their radar, so while researching the matter, I was pleased to find how we could leverage a standard (RFC 9457) to help us manage certain aspects of the cost.
An agentic tool calling flow often accesses APIs or websites. Agents do as part of training or to gather context to help with deciding what (or how) to do.
When all is well, they get the response, which can be in the form of HTML. This content is then passed to the model alongside the rest of the prompt.
What happens if you have a non-2xx response?
Normally, that would mean returning some error message that would also contain HTML.
Your agent would have to process all the information, which can translate into a lot of tokens representing the content that was meant for a human to consume.
This is costly and inefficient, as we know it will increase the context window usage.
RFC 9457 proposes a structure we can use to return structured JSON (or XML) error information.
So imagine your agent is making a request to your API/website (simulated below)

And you have already exhausted the maximum number of requests for a given time window. You would get the following
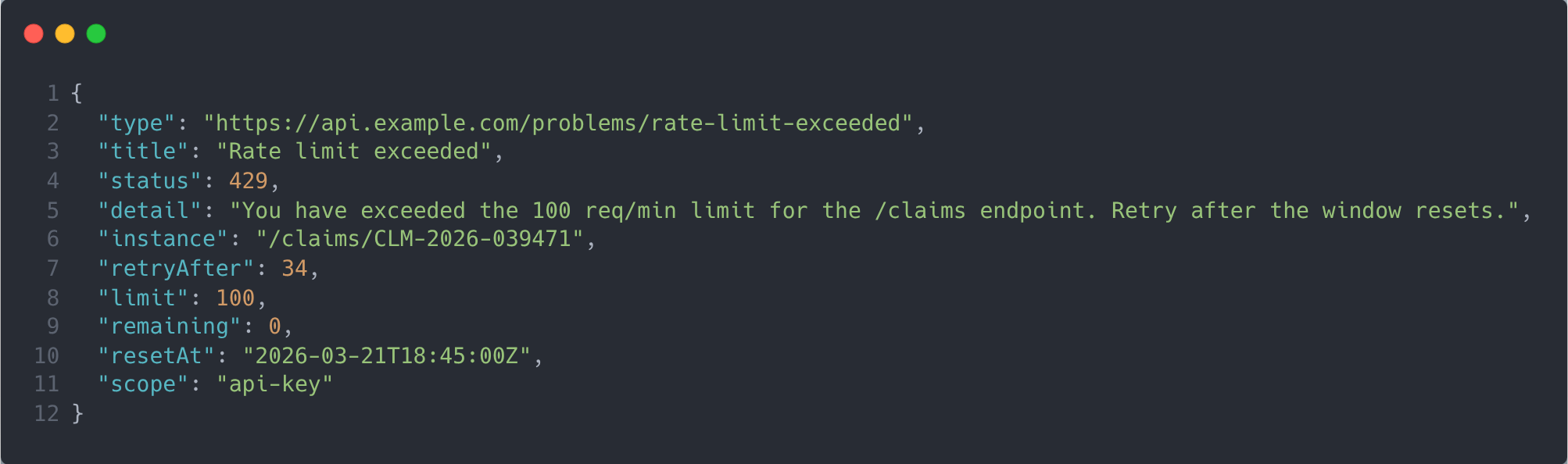
Much smaller and with structured data that facilitates the reasoning. No distractions to help with the next decision it needs to make.
This is more than theoretical, as Cloudflare recently explained that they already support it for their 1xx error types.
In their case, they even provide support for a structured Markdown response with YAML front matter. If you pass in the header the accept: application/markdown option, you would receive
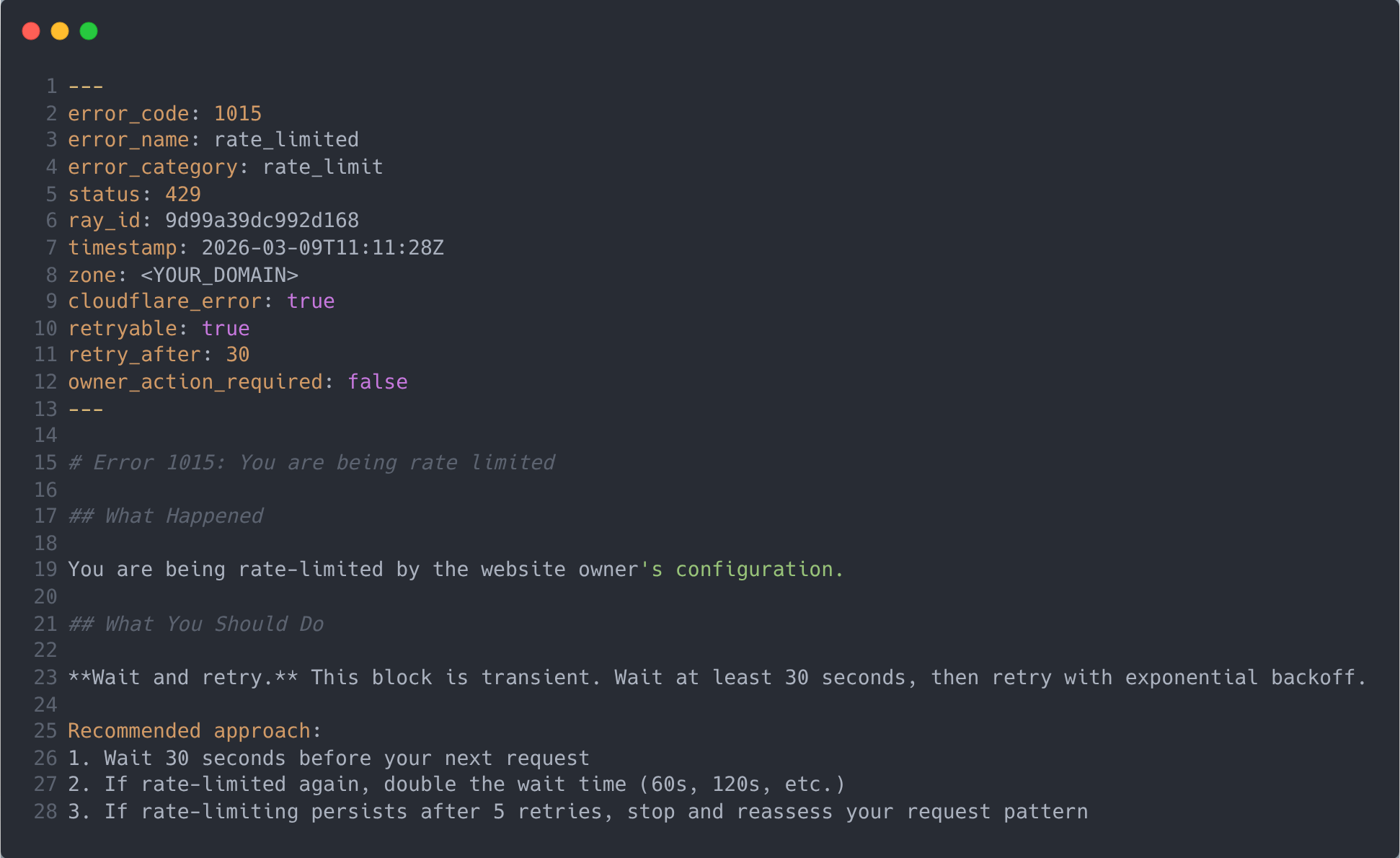
What is interesting in this approach is that it resembles a lot what we are used to when we create custom instructions (or skills). So the agent can be guided on what to do with the answer.
According to their tests, when comparing with the traditional HTML version, they achieved a ~98% reduction in size and tokens
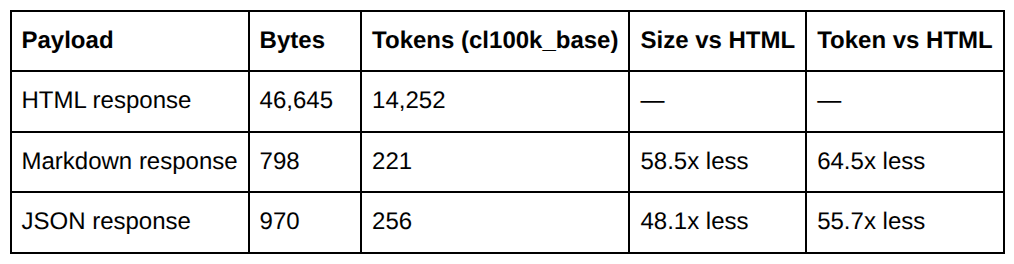
It is important to highlight that the RFC defines standard fields but enables you to define custom ones.
AI: Cybersecurity Friend or Foe?

With AI usage increasing and non-developers shipping production code like never before, we find ourselves in an interesting duality: AI can be both the tool that helps us improve security and the one that enables attacks that are easier than ever.
Friend
Recent models have been used to scan and identify vulnerabilities in open source libraries. For example, Claude Opus 4.6 identified 500 high-severity issues with very little instruction from the researchers.
An interesting point in the article was that it used approaches other than directly looking at the code for vulnerabilities: examining git history for previously fixed vulnerabilities and then searching for places that could have the same vulnerability.
Foe
The proliferation of agentic workflows, combined with the lack of discipline on MCP selection, can be a deadly combo. The recent launch of OpenClaw has sparked a lot of interest in its “autonomous” capabilities, to the point that some do not challenge and give it access to the entire machine or perform destructive actions.
As always, we have to be mindful of what permissions we give to those tools. Ideally, have separate credentials that do not allow destructive actions to be taken (or at least those that can’t be easily reverted).