Integration Testing Techniques
Plus discussing WebSockets, SSE and the eventual rise of the 0.1x Engineer

Testing applications, especially distributed/event-driven ones, is challenging given the many services involved and the asynchronous nature of the communication.
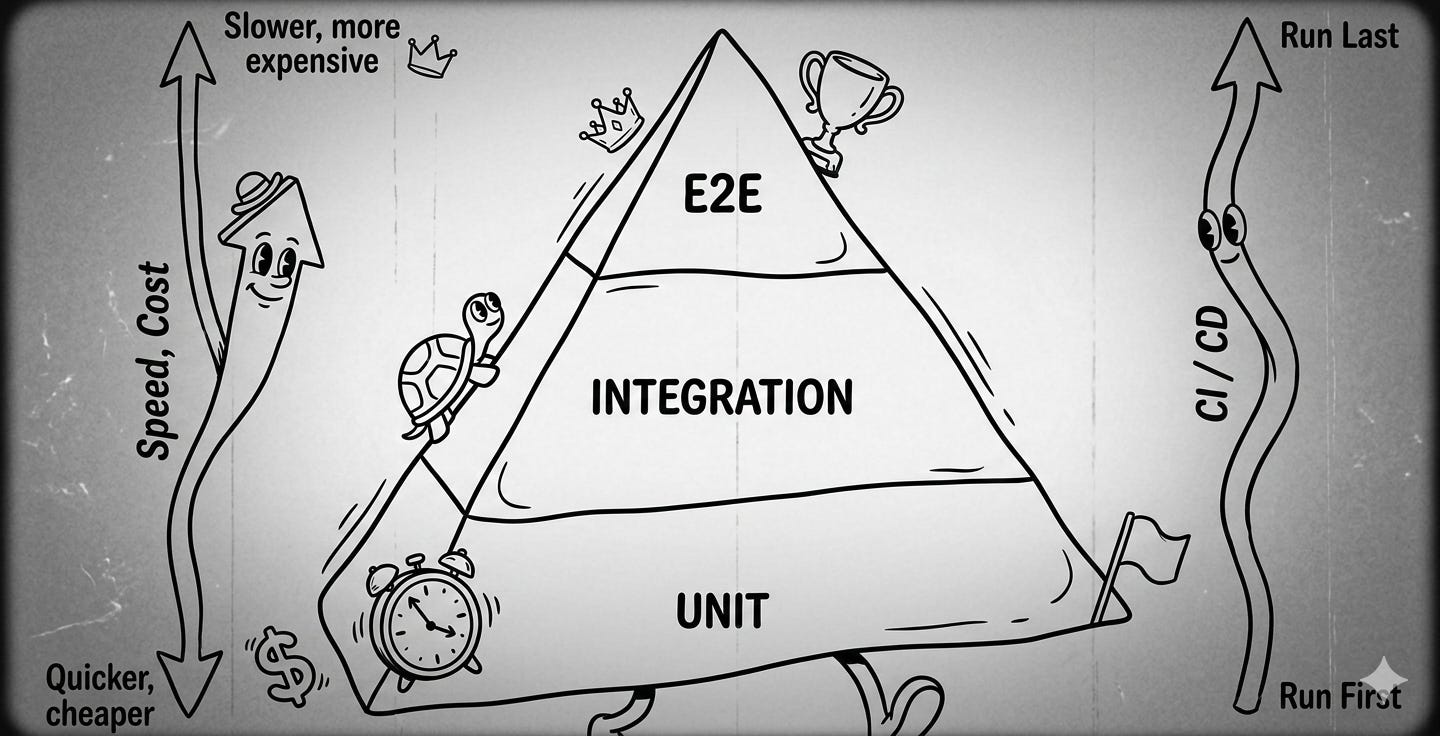
Using the traditional pyramid approach, we know that we have unit tests for our individual components, relying on mocks for those that also have external dependencies.
At the other end of the spectrum are the E2E tests, which look at the process as a whole, trying to confirm if the expected outcome took place. Testing this requires having all services and the connecting messaging system all set up in tandem.
No wonder those are the slowest and most expensive tests you have. On top of that, when they fail, it is not immediate to find out where the problem took place. So, how to increase your confidence in your system and address this “limitation” on E2E?
As this article reminds us, integration tests can help. But what would that look like?
Using the example from the article, one approach is to look at the parties involved in a given use case and split the integration tests at the edges of the messaging solution.
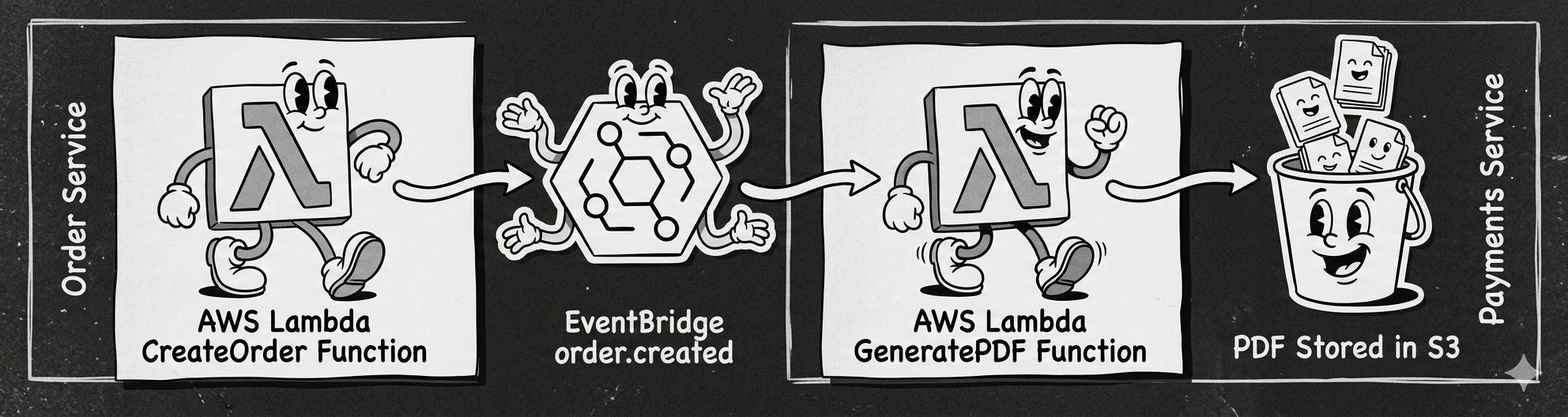
In the example, we would have two integration tests:
Between the Order Service and the EventBridge
It would confirm that once the create order request is processed, an event is sent via EventBridge.
To test, you create a rule to set up a wiretap in EventBridge, directing a copy of all messages of Order Created to a test Queue and provide a consumer for that queue.
Between EventBridge and Payment Service
It would confirm that once an event (Order Created) is available, the PDF would be generated
To test, you inject an Order Created to Event Bridge and assert the PDF was created.
If either one fails, it is easier to spot where it took place and target the investigation on the reasons why.
One of the benefits of serverless solutions combined with infrastructure as code is that the costs can be drastically reduced as you pay per volume, and the testing infrastructure creation can be automated and is ephemeral.
You configure your CI/CD pipeline to create a new EventBridge, SQS, and tear down at the end of the execution.
If you want to know more about other messaging solutions, check my series on SQS, SNS, EventBridge, and Kinesis here.
Using WebSockets for two-way communication
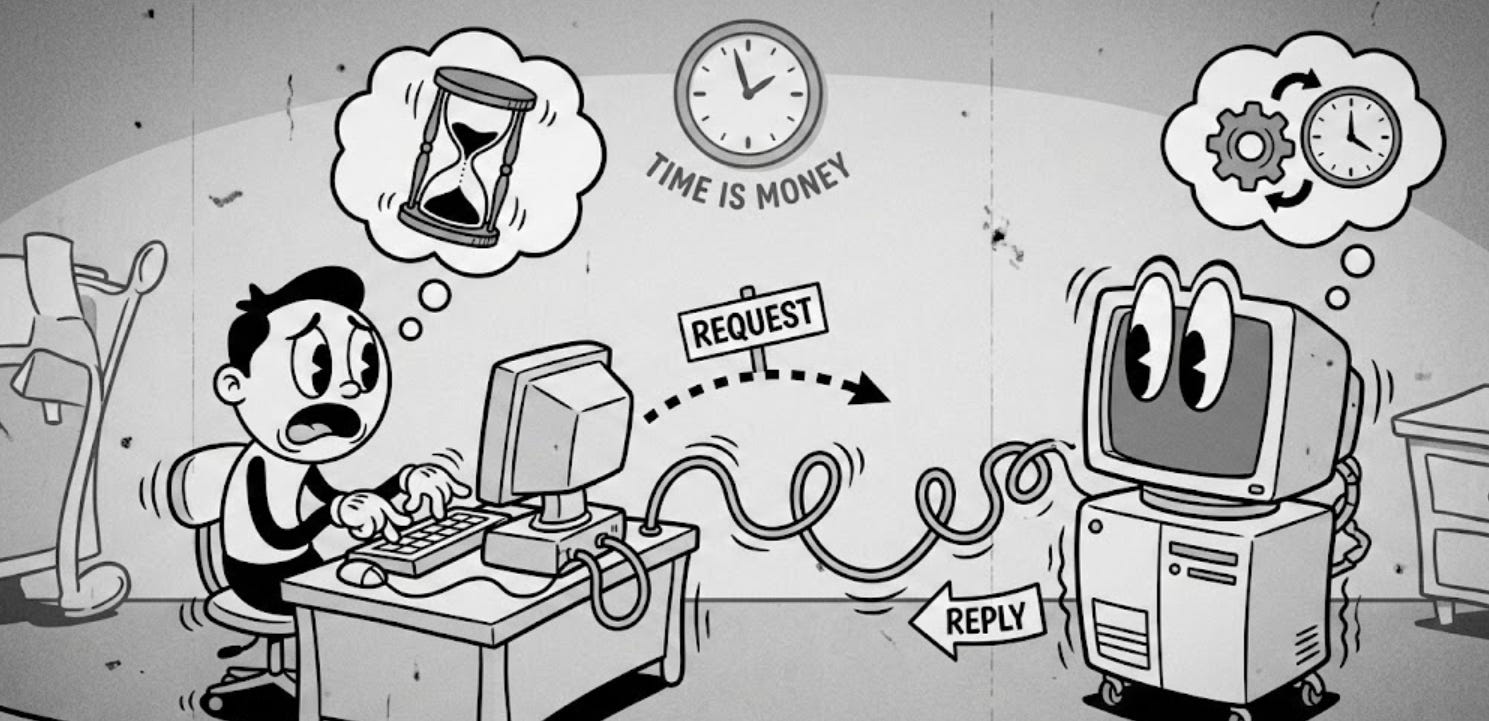
The way we interact with our online applications and websites has followed, for the most part, a simple mechanism for more than 30 years. For each interaction you do that requires some external dependency, you send a request and wait for a response.
Over the years, we introduced some variations to this to improve the user experience. Gmail made Ajax, which used XMLRequestObject, popular by providing ways to avoid the blank page associated with a full page reload. Single-page applications (SPA) came next as a way to improve the perceived usability by loading and executing more complex logic at the client side.
Despite all of that, the “norm” is still send a request for the needed information / external interaction and wait for the response.
But what happens if the execution of this request demands some heavy computation? Network connections time out after a while. Idle connections also consume resources that could be used for other requests.
The traditional approach to overcoming this limitation is to introduce a polling mechanism. Essentially, the request you sent is replied to immediately, just to indicate the request has been received and likely provide some way for you to inquire about its state later - some sort of ID.
Then you establish a loop on the client side that continuously sends a request to check the status of the request.
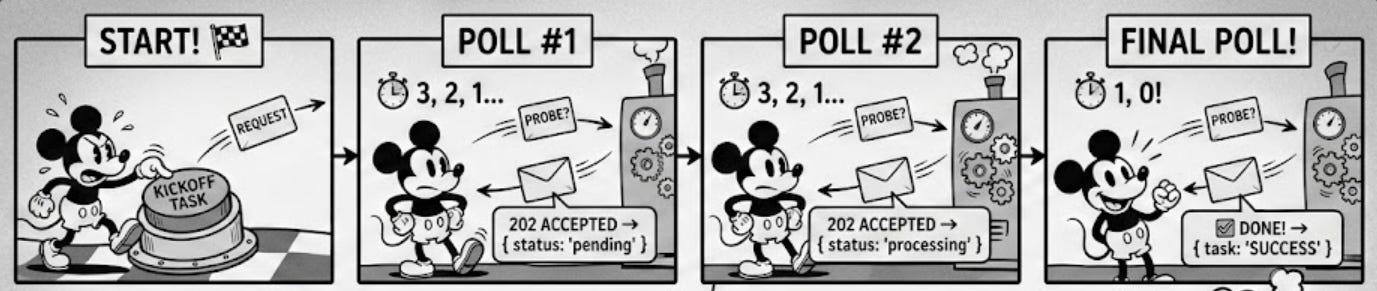
This addresses the problem but has a clear shortcoming: it will waste resources. Since you do not know when it will be ready, you will keep sending requests just to get an answer that the request is still in progress. This can be prohibitively expensive in a serverless case, where you will be billed for those requests. You can check this article for more details.
There are at least two other alternatives that try to alleviate this: WebSockets and SSE.
With WebSockets, you have a bi-directional channel that enables your server to push data (messages) to the client, which in our example is your client’s browser, as new information is available.
Another option is to leverage server-sent events (SSE), in which the client establishes a unidirectional channel with the server, enabling it to push data through it as events.
Both cases work with SSEs, being simpler to implement when all you need is to receive these notifications from the server without the client continuously sending more data in response to these notifications.
The rise of the 0.1x engineer
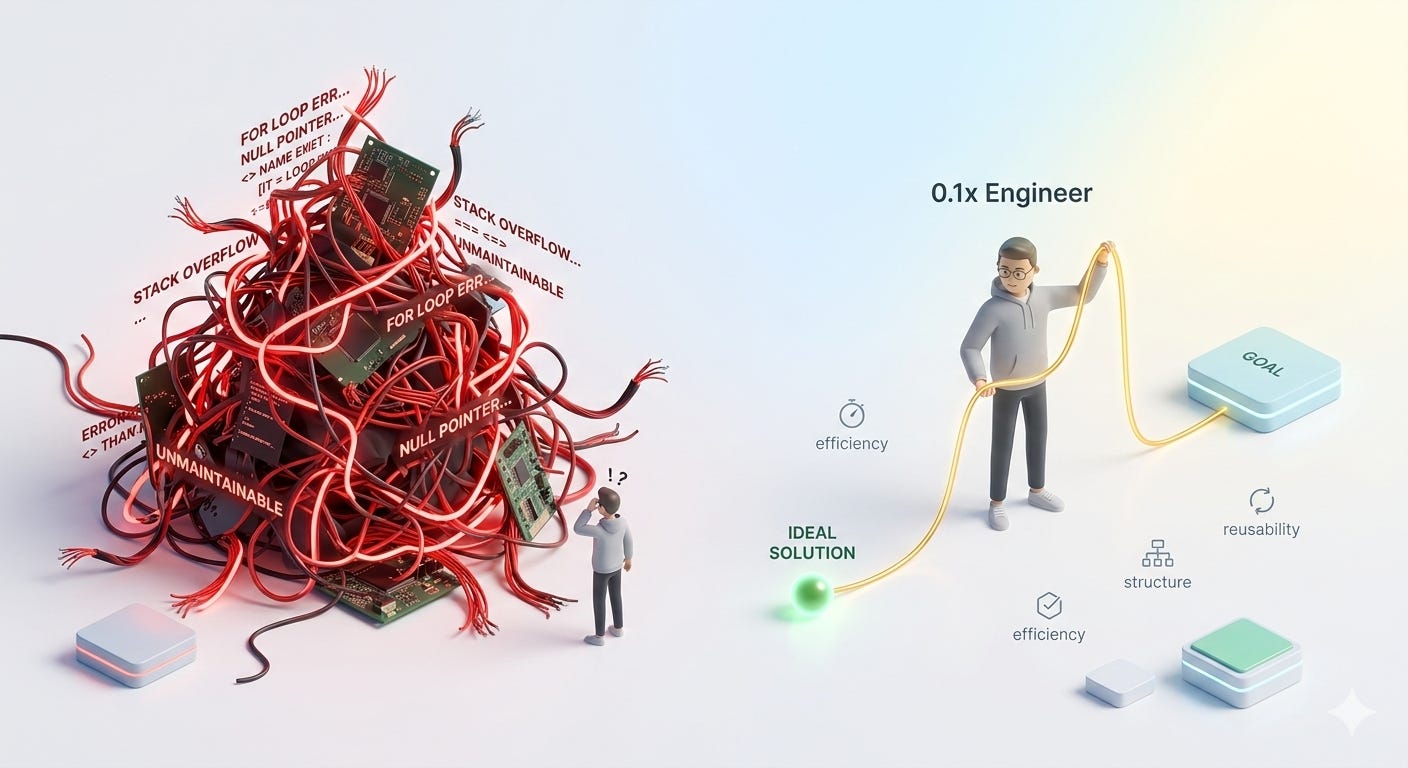
Every other week, we seem to be presented with a new tool/framework that will change everything with the promise of mythical 10x (or 100x) gains in productivity.
I am the first to admit that when it comes to producing code, the current set of tools + models can help a lot. They reduce the cost of experimenting with new ideas and shorten the time to market of well-defined solutions. But it is far from the bed of roses that you may be led to believe if you trust blindly what you read/see on social media platforms.
I came across this tiny article that reminds me how easy it is to generate bad code and foster complacency. You are generating so much code that it is all too easy to let poor implementations grow bigger and bigger to a point where understanding what is happening is no longer possible or extremely time-consuming.
In this context, the 0.1x engineer is the one who can prompt to generate the least amount of code, while looking for reusability and maintainability.
Some may argue that AI assistants will take care of that as well, but today it still depends on us having the knowledge to discern good from bad and steer the solutions to where we would want them to be.