Important Edge Cases For Your API Design
Plus OpenAPI 3.2 released, new PostgreSQL 18, Why is so hard to find a new job in Tech and Leaving ElasticSearch

“The happy path works fine. Then production happens.”
Software development is hard for many reasons, and the unhappy path/edge cases are there to remind us why a more defensive way of approaching the craft is needed.
In a world where APIs are everywhere, this article brings to light some cases often overlooked or unknown to many developers and how each one can affect you in ways your application would not expect.
Here are some of those I found most interesting:
Range Header Handling
Range headers are used to help with resuming downloads and enabling the downloading of file chunks. More established solutions, like nginx or Apache, handle those headers correctly, but you have to do the work yourself if you plan to develop a custom code that handles downloads.
You should check for the number of ranges for the size of content you are serving and establish an upper limit on the number of ranges you can process.
Content-type Enforcement
JSON is widely used, and sometimes frameworks offer lenient implementations while parsing its contents. That can open security breaches or unexpected behavior to our applications that take the content as valid, just to fail at the inner layers of execution.
One way to minimize the risks by forcing an early/strict validation is to specify the type of expected payload in your UI layer — for example, a SpringBoot controller.

Method Not Allowed Should Tell You What Works
This is a small, but helpful change you can make to your APIs. If you encounter an error because someone sent a request to a valid address but an invalid method, your response should be 405 with a list of the methods you do accept.
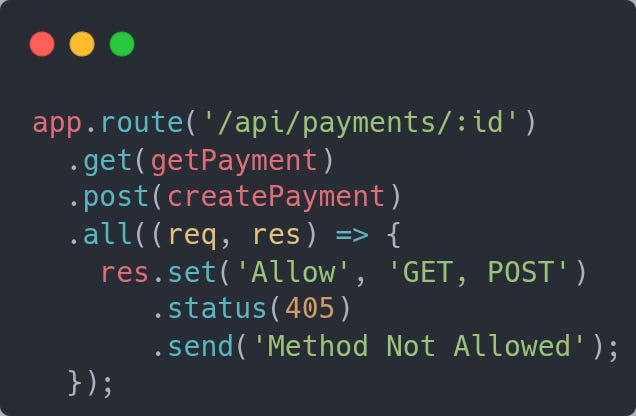
So instead of a 404, the 405 and the Allow methods would self-document your API’s response in the case of this type of error.
Compression Configuration Is Never Where You Think
This is an easy one to miss: compression enabled at the web server for the content it outputs may not be used at all.
Since the content we produce or host on our web servers can be text-based, applying compression has been an easy way for a long time to deliver things faster: compress the output, it takes less time to travel the wire and reach the destination.
However, since in many cases you have an API gateway or reverse proxy sitting in front of your APIs, if you enable compression at the web service and the edge is not configured to do the same, then no real impact is expected.
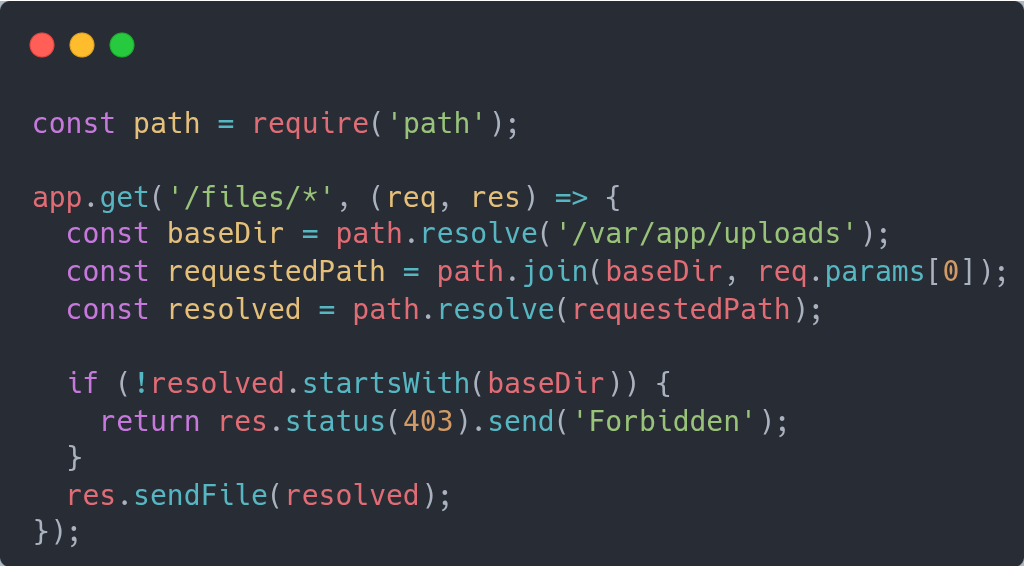
Path Traversal Lets Attackers Read Arbitrary Files
If you expect to receive the name of a resource that resides in the server’s local filesystem, it is important to know you may be vulnerable to path traversal attacks.
Imagine if the input were something like this, and you were to enable a download/visualization
GET /vpn/../vpns/cfg/smb.conf HTTP/1.1
GET /vpn/%2e%2e%2fvpns%2fcfg%2fsmb.conf HTTP/1.1
There are many solutions, from whitelisting, hashing names, to validating the absolute path ahead of reading the contents, like the example below.
For a full list of other edge cases, check the original article here.
Databases
PostgreSQL 18 Released
PostgreSQL is one of the most versatile open source databases. From traditional relational offers with JSON capabilities to vector embedding support. All of that while sporting features that you are only used to find in more enterprise versions.
With the new version 18, the number of reasons to adopt it just increased.
The claims are of an up to 3x performance improvement, largely due to a new I/O subsystem with a less disruptive upgrade process, aimed at speeding up the adoption of new versions.
One of the nice features is the support to UUIDv7 generation supported directly via the uuidv7() function, addressing the indexing ID issue that regular UUIDv4 has.
The list of main advancements:
- Asynchronous I/O
- Faster upgrades
- Query performance enhancement
- Virtual generated columns
- OAuth authentication support
See the full list of features and a guide to help you upgrade here.
API Development
OpenAPI v3.2 Released
OpenAPI is probably the “de facto” standard for documenting APIs, and a new minor release (3.2) is available.
The features that I found more relevant to my use cases are:
Expanded Tags
The Tags object has a summary property for a short description, a kind property for classification on the purpose, and a parent to allow nesting of tags.
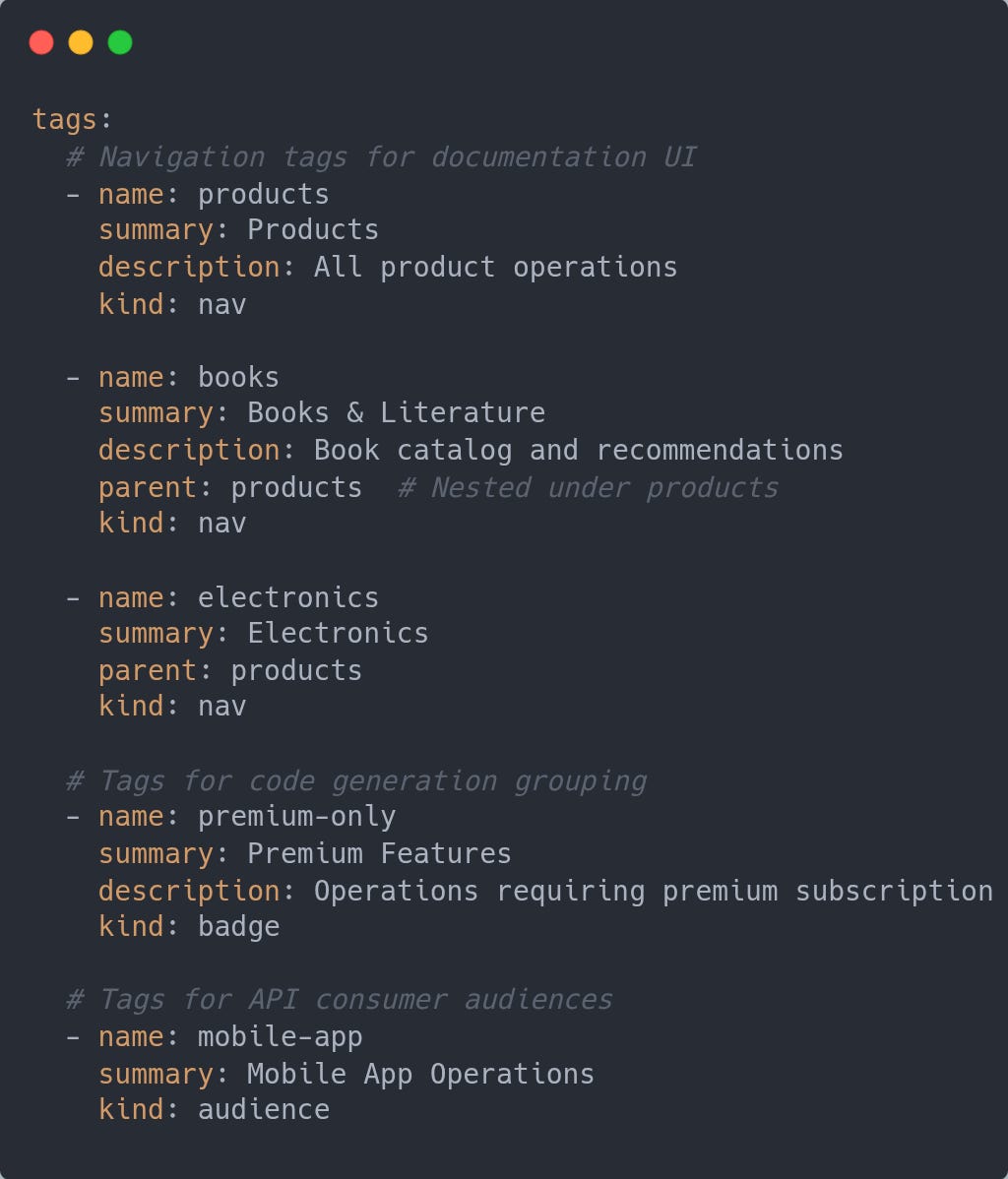
Why It’s Important
Better Documentation: Create hierarchical navigation structures in API docs (Products → Books, Products → Electronics)
Selective Processing: Tools can filter tags by kind - documentation generators use “nav” tags, code generators might use “badge” tags
Multiple Taxonomies: Same API can have different organizational views without conflict (navigation structure vs. feature badges vs. target audiences)
Cleaner APIs: Separate concerns between what developers see and what tooling processes
Support for Query HTTP Method
Remember when you needed to use a POST method with your /search capabilities? Well, not anymore…
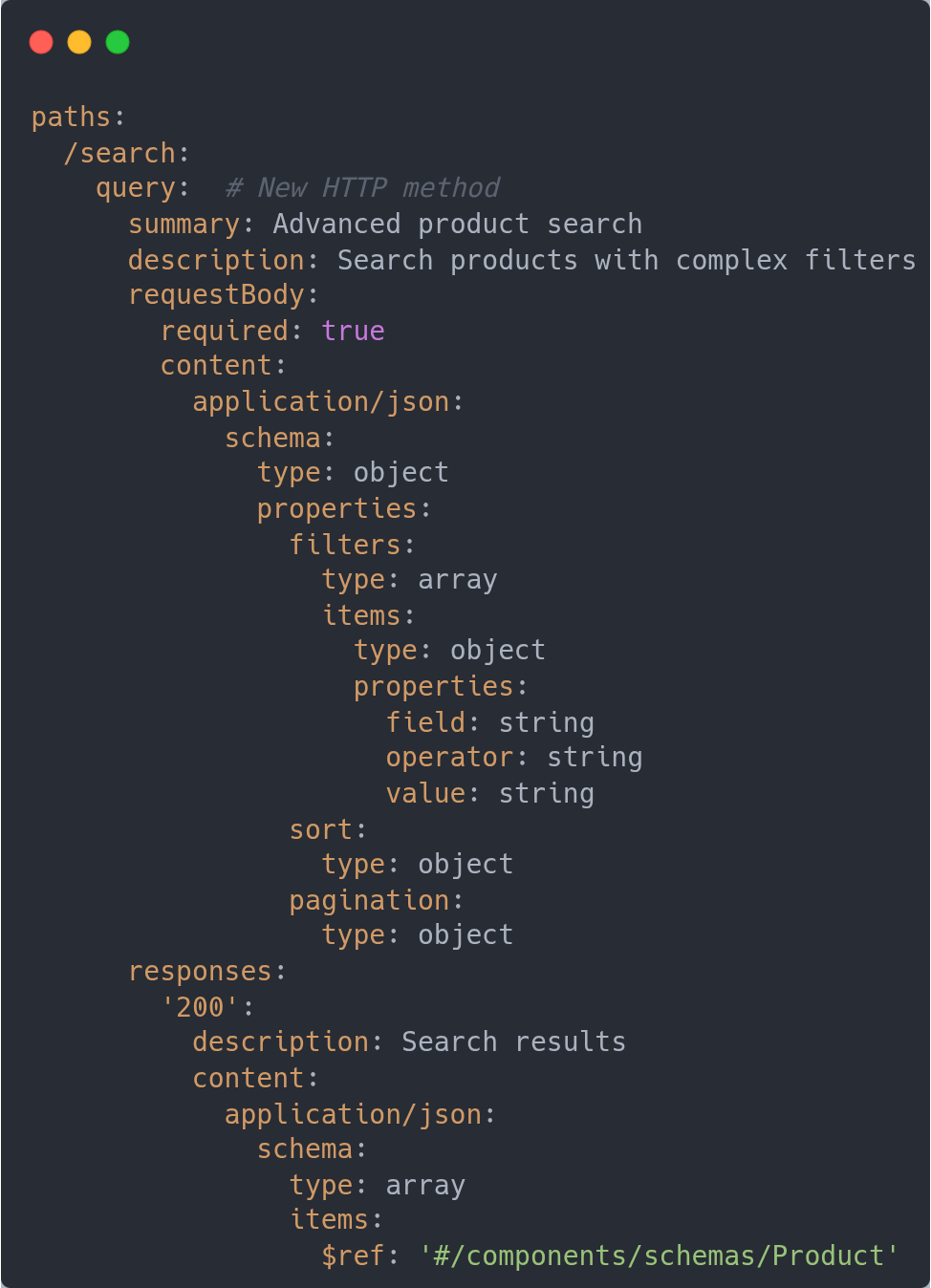
Why It’s Important
Safe & Idempotent: Unlike POST, QUERY is safe and idempotent (can be cached, retried safely)
Complex Queries: Send structured queries in the request body instead of cramming them into URL parameters
Security: Sensitive search criteria don’t appear in URLs/logs :)
Semantic Clarity: Differentiates queries from state-changing POST operations
More More…
There are more enhancements focused on making streaming data specification supported as a first-class citizen, adding support for non-standard HTTP methods, introducing a queryString keyword to better organize query parameters, and OAuth improvements.
Software Development Career
In a Sea of Tech Talent, Companies Can’t Find the Workers They Want
It is interesting how things can change in a relatively short period. If you go back 2-3 years, the tech market was in a frenzy, with companies in a hiring mode that fueled bizarre offers and a lot of mobility. Fast forward to 2025, we seem to have a completely different picture, with a continuous stream of layoffs and a generous impression that the “party” is over.
The popular opinion is that AI i the culprit, while others, like myself, think AI is just a part of the explanation. At the same time, [this](https://www.wsj.com/lifestyle/careers/in-a-sea-of-tech-talent-companies-cant-find-the-workers-they-want-76b7983a?st=oyrGKz&reflink=desktopwebshare_permalink&utm_source=tldrnewsletter) article, points out an interesting contradiction: while there are so many tech workers available, companies still complain it is hard to find good ones.
According to the article, in the US alone, the number of computer-related degrees doubled from 2013 to 2022. Meanwhile, most of the big tech companies (FAANG) have had and continue to have layoffs. It should mean there is an ever-increasing pool of qualified professionals up for grabs.
The (sad?) reality is that with the focus on AI, and the bet that it will be the most transformative technology of recent history, you have a divide between those who have AI skills and those who don’t. It is not hard to guess who is being preferred in the job search these days.
The challenge now seems to be, what effectively should you do in this scenario? Realistically, if you are one who has been avoiding AI due to its hype, I would say start practicing beyond asking ChatGPT/Claude for support. But please don’t stop there!
If you are a developer, find ways to incorporate AI that are meaningful and helpful, learn concepts such as MCP, RAG, and where they could be applied to deliver better solutions.
Architecture
Instacart Consolidates Search Infrastructure on PostgreSQL, Phasing out Elasticsearch
Dealing with complexity is one of the many challenges we face as architects and developers. Sometimes this means revisiting well-established concepts and practices and seeing if there are different ways to achieve the same -- or better -- results with fewer moving parts.
One interesting example is this story, where Instacart revisited its dual setup, with PostgreSQL for relational data and ElasticSearch for full-text queries.
In their case, they consolidated both capabilities into PostgreSQL and achieved a 10x reduction in write workload, 80% savings in storage and indexing costs, and simplified their setup. Result? Reduced dead-end searches and improved customer experience.
While their results may not necessarily apply to all use cases where ElasticSearch shines, it is interesting how they approached the semantic search capabilities by leveraging the pgvector extension.
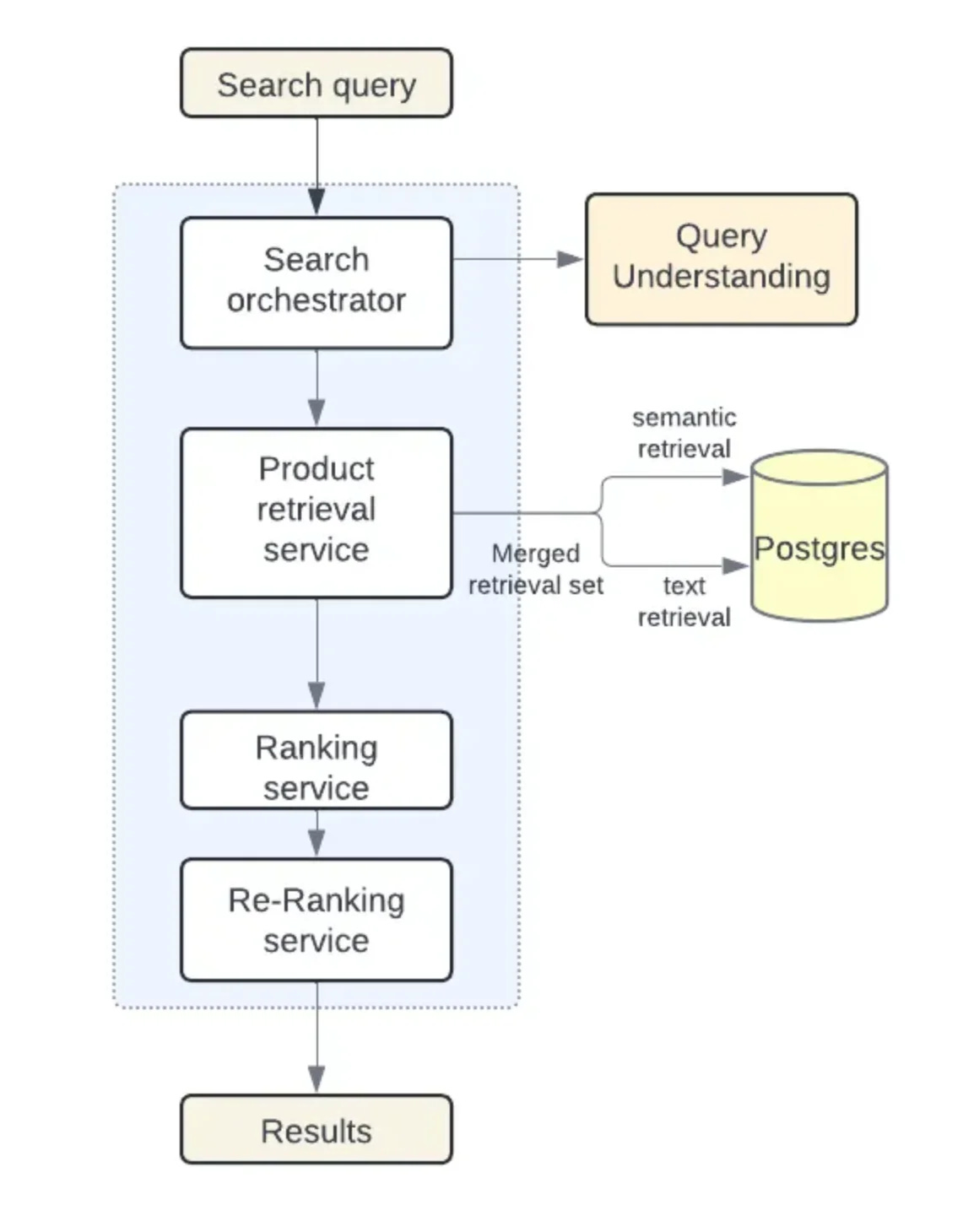
By using the solution, they avoided, among other things, the need to keep data synchronized between the relational solution and ElasticSearch.
This can’t be overlooked, as it is a source of issues whenever you have delays due to higher traffic or some missing data that needs to be resynchronized between the two.
The article describes the approach they used to migrate, with the obligatory creation of a lab-scale cluster for experimentation and as a way to reproduce production-like traffic, and then assess how pgvector and other components behave under similar conditions.
This should be dev 101 series… I am closely looking forward for next part ✨✨