Domain-Driven Refactoring
Plus thoughts on LLMs and software development, EventStoreDB x Kafka, Node.js embracing types and more

If you are involved in software development or technology in general, you will probably have been exposed to a myriad of patterns, standards, and practices. Not all of them survive the test of time or simply fail to get traction for one reason or another.
As one responsible for introducing some of these novelties to teams, I am always curious to understand when something fails to be adopted, especially when its benefits are supposed to be 'evident'. One of these is domain-driven design.
While looking at the reasons for the failure, I tend to find the overload of new concepts (entities, value objects, aggregates, repositories, etc) and the underlying code structure to be the culprit. All of a sudden, we are trying to achieve a level of cohesion and clarity by using these concepts while trying to uncover our domain at the same time.
I have found Jimmy Bogard's article on domain-driven refactoring to be a good way of approaching your application development. The TLDR is don´t try to achieve it all in one shot, instead start with the simplest solution possible and refactor your way around it until it reaches its ¨final" form.
In his series of articles, we can see how a solution, originally dumped as part of the controller, gets progressively changed.
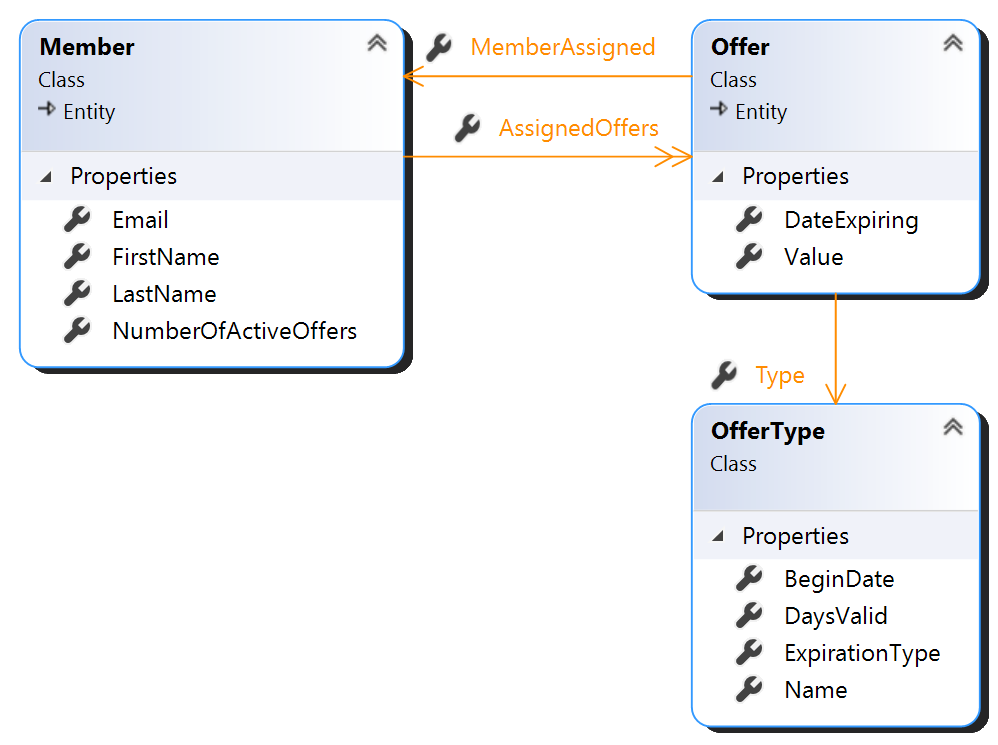
In his journey, after getting the controller working, he refactors the long method (the controller handler) by identifying the parts of operations it executes.
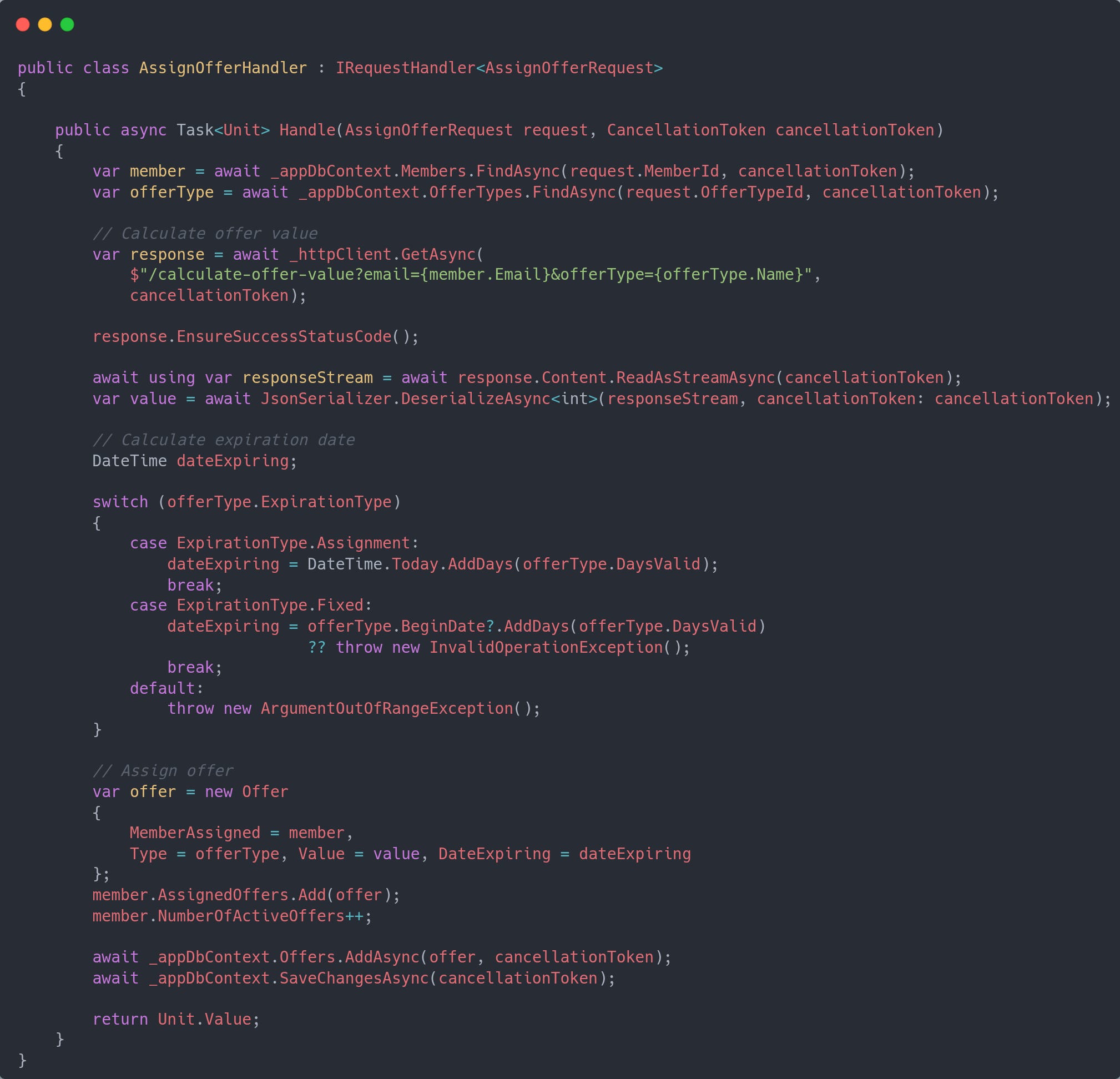
Then by extraction and composition you move the parts like below
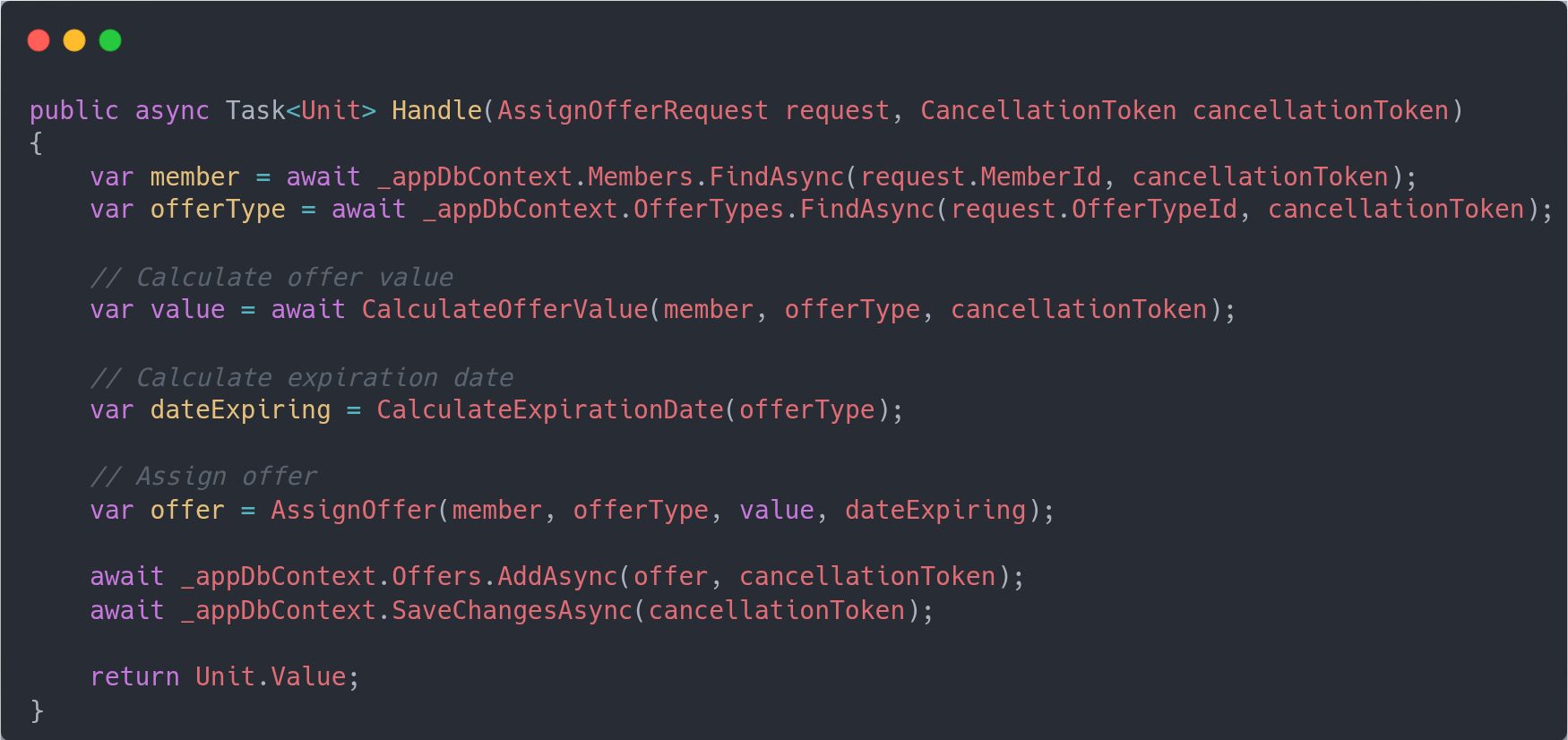
So far not much DDD is going on, but this is then when you start looking at those groups and, for example, start moving the code from the controller as separate service.
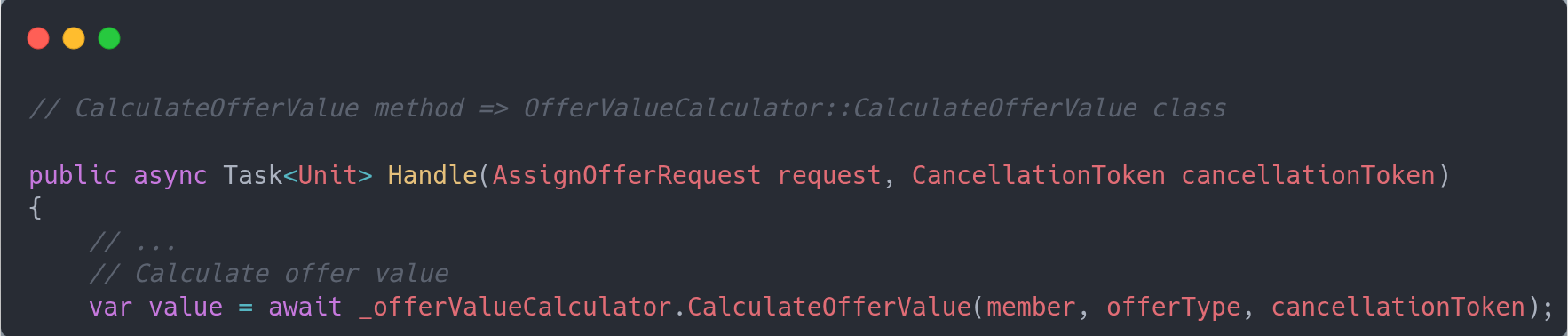
Then it goes on the other domain concepts, with behavior being push toward the entity/value objects. In this example when you assign an offer you do so to a member, so it suggests we should have a Member entity who should own the logic that is responsible for that operation.
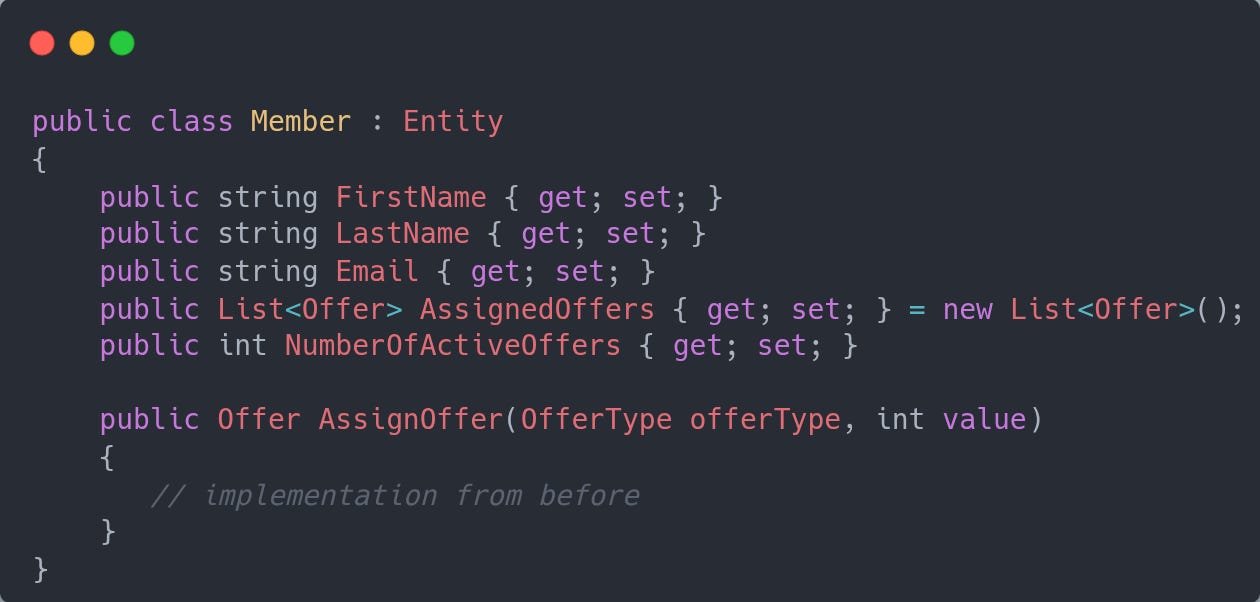
You would repeat this process by moving the validation rules into existing or new concepts (entities, value objects) as you uncover each one of them, and keeping the working state of the system.
One of the important pieces here is that you avoid making too many commitments upfront when your own understanding of the domain is still forming. At the same time you tend to always keep producing working code, which helps with agile approaches.
AI
Some thoughts on LLMs and Software Development
The debate on AI and its true benefits continues at full speed. Unfortunately, those with the strongest predictions for it can´t be fully trusted as they are selling AI services themselves :(
In times like this, I tend to focus on those opinions I respect and seem to offer them from a neutral ground. One of these is Martin Fowler, which in this article shared his thoughts on LLM, specifically from a software development angle.
My highlights on some of these thoughts that resonate with me:
- Surveys on the topic do not take into account how people use LLMs
This in interesting because how you use AI tools can definitely influence the usefulness of the output. If you stick to the auto-complete feature the results are highly variable and often perceived as a gimmick. I have had good completions and some so off that made me turn away.
- AI is a bubble like all major technological advancements
AI bubble will pop with near 100% certainty, taking with it many companies. What is uncertain is when this will happen and which companies will survive. The triad technology, scale and data will be a factor to indicate that.
- Hallucinations are not a bug but a feature
To me this is an interesting statement, but the reasoning seems to be that given the probabilistic nature of LLMs, you should consider asking the same question twice and compare the answers.
Maybe the differences between the answers will help enlighten and choose the best one.
Jevons' Paradox Can Be Good?
Jevons' paradox indicates that when technology makes a resource more efficient, its usage may go up offsetting any of the gains we obtained at the beginning.
This paradox has been recently used with AI, where companies like Google, Meta compare the amount of water that is used for a single chatbot session or prompt execution. For example, Google has mentioned 33x reduction in electricity consumed per prompt in the interval of one year. Yet, the total consumption has gone up with the widespread of AI usage, attributed to cost reductions among other factors.
The initial conclusion is that Jevons' paradox is at work and we will end up in a worse place despite -- or because? -- the same technology progress.
This is where I found this article's approach an interesting counterpoint. The first thing it establishes is that for something to be bad it means that the net result must be negative. And this is where things can become more interesting as advancements made possible by the use AI can offset its usage in other areas.
For example, Google Maps can help cars to reduce fuel consumption way more than it costs to run in data center electricity.
Additionally, the total data center emission is projected to reach 320M by 2030, which should represent around 1.3% of global emissions. So imagine that if AI helps us to reduce emissions -- better materials, energy grid optimization, transit, etc -- by more than 2%, we would already be on the positive side.
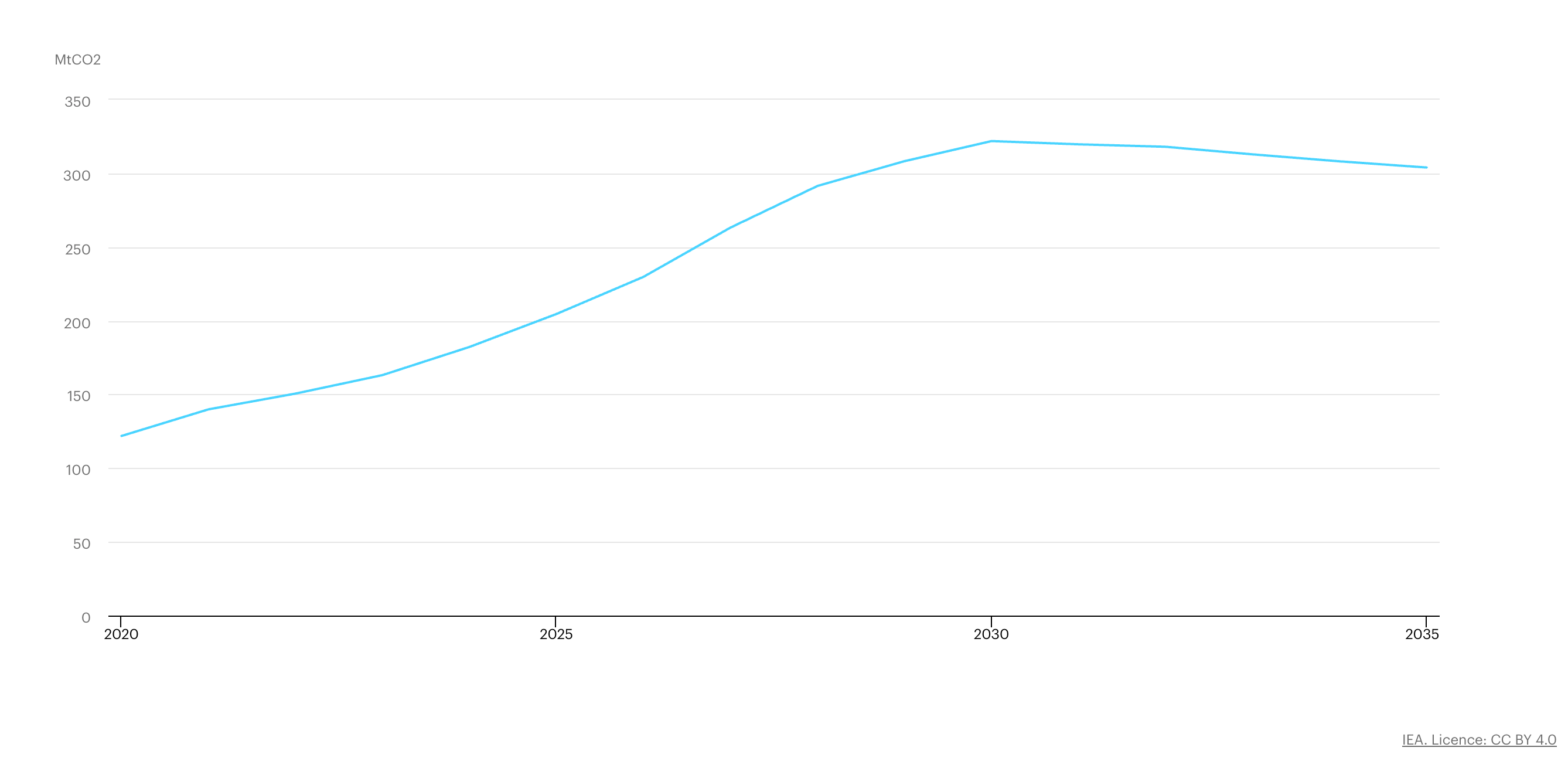
The bottom line, is while I agree that it is too soon to claim AI to be the savior, it is equally too soon to call it the bad guy.
Architecture
EventStoreDB x Kafka
Event Sourcing is a powerful pattern that has, at his heart the notion that you persist the facts (events) about the entities your service is responsible for. Then you need to replay them when asked for the current state of said entity.
As you can imagine, the persistence chosen with this is important, and while in theory any one that allows you to save the events and retrieve them when needed can be used, a common issue is trying to leverage Kafka to do so because of the confusion of what event sourcing is x event streaming.
This article tries to showcase why the difference is important by comparing EventStoreDB (now known as Kurrent) and Kafka.
Kurrent has a definition of a stream ID that enables you to retrieve events (all or just the latest n) of that stream. In this case think of each stream containing a single entity lifecycle. Do want to reconstruct the current state of Order X? Retrieve the events from Stream ID X.
It has a built-in concept of optimistic concurrency control as it leverages the ExpectedVersion attribute, making sure if a newer change already exists, adding this event will be rejected.
Kurrent supports the concept of projections that can group streams into a single new stream, allowing you to subscribe to this new stream and receive, for example, all changes for Orders.
Kafka while providing the distributed, append-only log that seems to fit the bill on the ingestion side, does not allow us to natively handle concurrency control at the persistence, relying to the application to ensure that. It also does not offer built-in capabilities to enable effectively to retrieve events for a specific entity ID.
While there are Kafka setups that can mimic the behavior of Kurrent, so far all of them seem to add more complexity and cost.
Before you decide to go with any persistence, assess if and how they support the following features
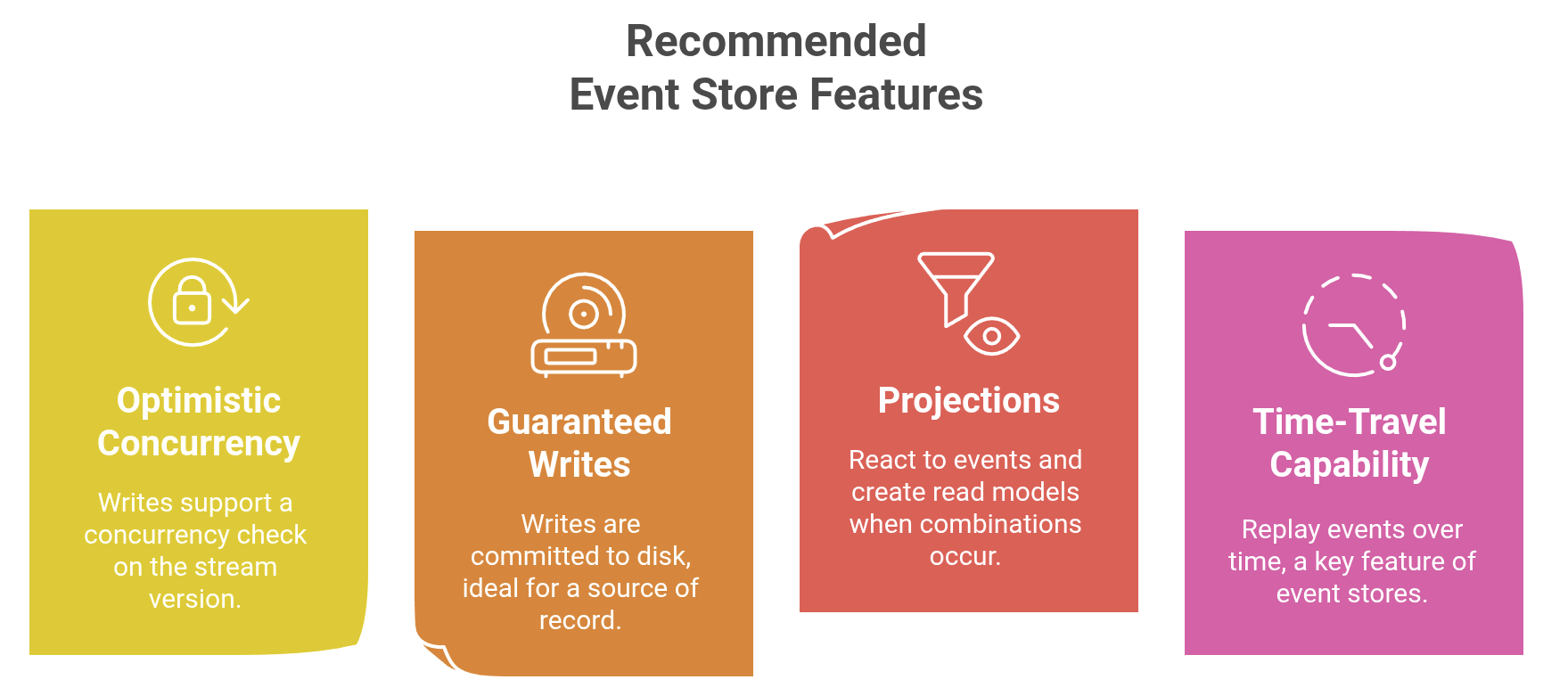
At least you will make the decision knowing of the trade-offs from the start.
Development
Node.js Moves Toward Stable Typescript Support with Amaro 1.0
If you work with web development, the combo Typescript + Node.js is one of the options available with the benefits of having the flexibility and familiarity of javascript, possibility of reusing code for both backend and frontend and a design time type safety.
However this is obtained via a collection of tools, one of them being a transpiler that turns your Typescript code into javascript before it can actually be executed.
This can be annoying and is one of the motivations for other runtimes, such as Deno, that support Typescript without any external tool. So goodbye tsc, tsx or ts-node.
Node.js team seems to have realized that Typescript support should be treated differently and has been making progress for a while, with experimental features that allow you to run typescript without the external tool.
With a recent release of Amaro 1.0 we seem to continue the progress of supporting typescript, which enables us to run when the dependencies inside node_modules are also in Typescript.
It is nice to see progress, but I feel the Node.js team should look more closely to what Deno has done. Embracing types, while being totally fine with not using them if you want + including standard tooling — batteries included approach — to me is the wining formula that Deno and some other modern languages have adopted.
Quote
“The advance of technology is based on making it fit in so that you don't really even notice it, so it's part of everyday life.” - Bill Gates