Documenting Your Event-Driven Application using Event Catalog
Making documentation a first class citizen

Documentation is one of those things that we all know we should do, but seems to always be relegated to the last spot in the priority list.
I believe it is partly because many fail to find the balance and either end up with too much, which becomes costly to maintain and outdated, or too little, and likely not useful enough.
Finding the right amount seems to be more like an art than a science, but it is important to recognize its importance, especially for distributed, event-based systems.
AsyncAPI appeared to close the gap on asynchronous systems, but Event Catalog leverages that with a more integrated usage that enables you to define and expose events, commands, and queries that your services emit and consume.
The intuitive way you can define and set of integrations enables sophisticated setups and automation to help you scale its usage even if you have multiple domains and services.
You can now more and follow a step-by-step documentation here.
Development
Zod Reaches 4.0
Probably the most insidious errors manifest themselves when an invalid input makes its way to the inner parts of our services. All of a sudden, a situation that should never happen presents itself, and our code fails because it expected things to make sense.
For Typescript-based services, the common mistake is to assume that because I am using a type system, I am safe. Because the types are stripped during the build process, any protection you had is null at runtime.
One solution is to add input validation at the edges of your service. To aid us in this endeavour, the solution I recommend is Zod, a lightweight library that has been adopted by many given its power and ease of use.
Zod 4.0 was released, superseding the previous version launched in 2021 with some notable changes:
Parsing improvements ranging from 6.5x for object to 14x string parsing.
Faster compilation (tsc) of 10-100x
Core bundle size reduction of 2x or 6.6x when using the new Zod Mini
JSONSchema conversion via a simple .toJSONSchema() call
Recursive object support
Built-in pretty-printing errors
Top-level string formats - no more .string().email() and welcome .email() directly

If you are using version 3, check the migration guide and start leveraging the new features.
Understanding the Law of Demeter
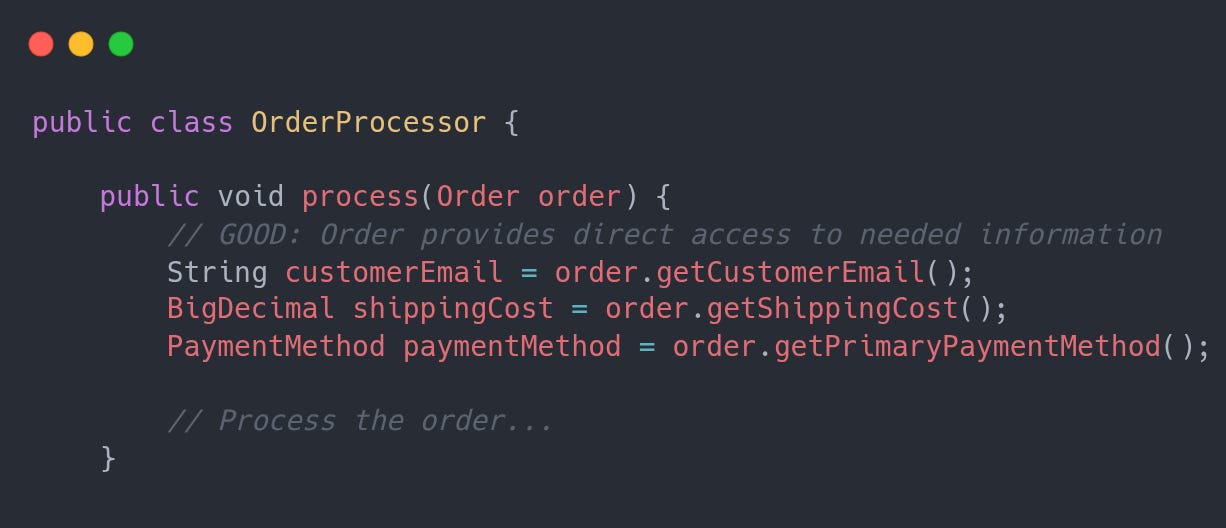
Consider that you have a code that looks like this

Pretty straightforward, right? No.
Can you guess what is the problem with it? If you said indirect dependencies, congratulations.
When we look at the Order processor, it needs to know that the Order has a customer and that this customer has a contact information.
Enter the Law of Demeter which is more like a guideline to help you identify and address the above. Only talk to your immediate friend! :)
Serverless
Validating Event Payload with Powertools for AWS Lambda (TypeScript)
Continuing with the theme of input validation as a way to fail fast and protect your domain logic without polluting it, let’s talk about AWS Powertools!
PowerTools supports multiple languages, and with TypeScript, it relies on Zod to help you add validation in the form of middleware or as a decorator.
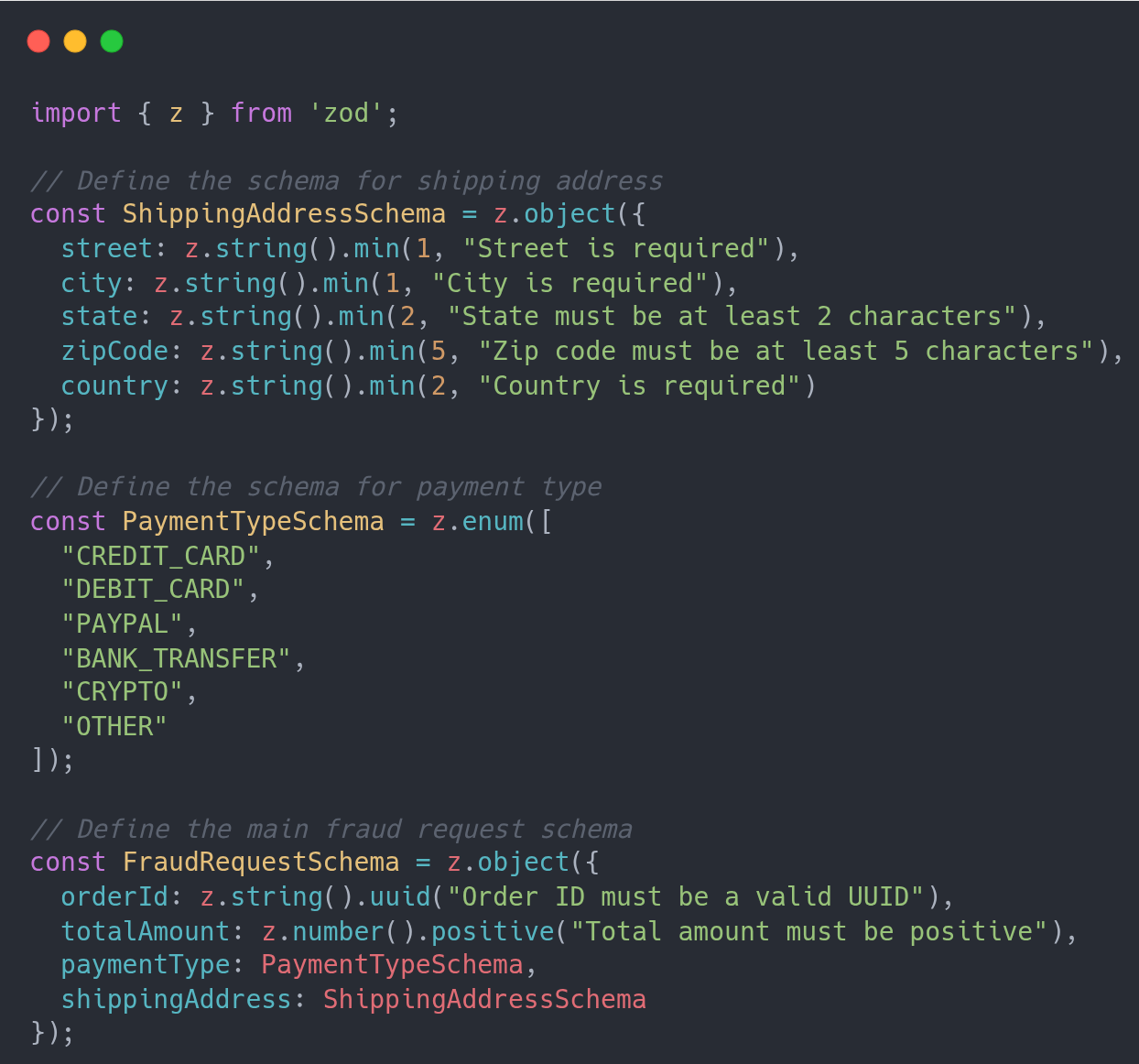
You define your Zod schema like you normally would
And then you use the decorator pointing to the schema that you just defined
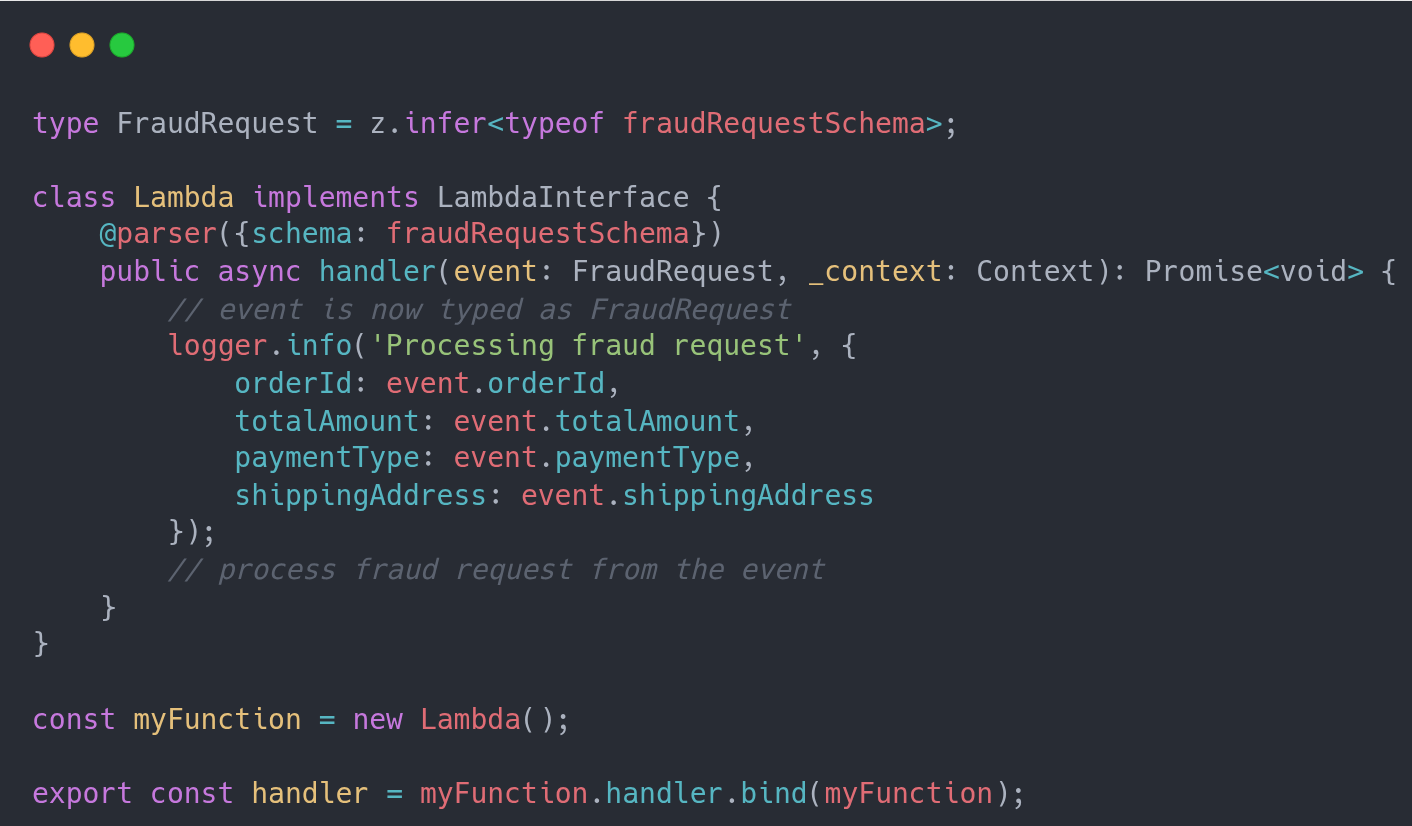
This makes it simpler to guarantee at runtime that your event payload conforms to the schema and focus on other aspects, as well as, if necessary, more domain-specific business rules.
But it is not all, as PowerTools includes pre-built schemas for the various event sources that can trigger lambda invocations.
You can even extend those schemas so you validate that not only the event you receive matches the format of the AWS service that triggered you, but the data it contains matches your domain specification.
Confused? Imagine we are using EventBridge to trigger the lambda. We have defined the schema for the data, the fraud request. But it will arrive in our lambda as part of the EventBridge payload.
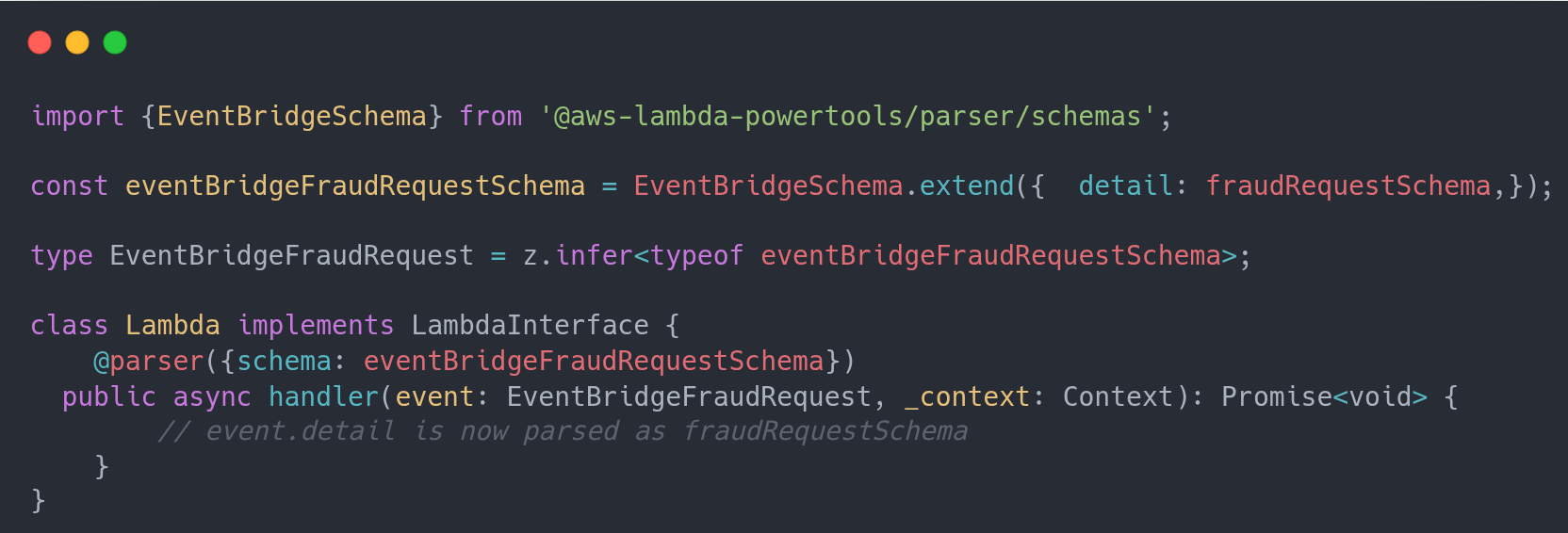
Because we are using Zod, you can define custom validators and more. Check the full details here.
Architecture
Hexagonal Architecture
Even though Domain-Driven Design and Hexagonal Architecture are two separate things, both are commonly used together. If alone, DDD can already be a daunting task to understand and use properly; imagine adding one more thing to it.
That is why I continue to recommend Herberto Graca’s article that does a marvelous job at introducing how Hexagonal Architecture concepts fit with DDD, and does so in a progressive fashion.
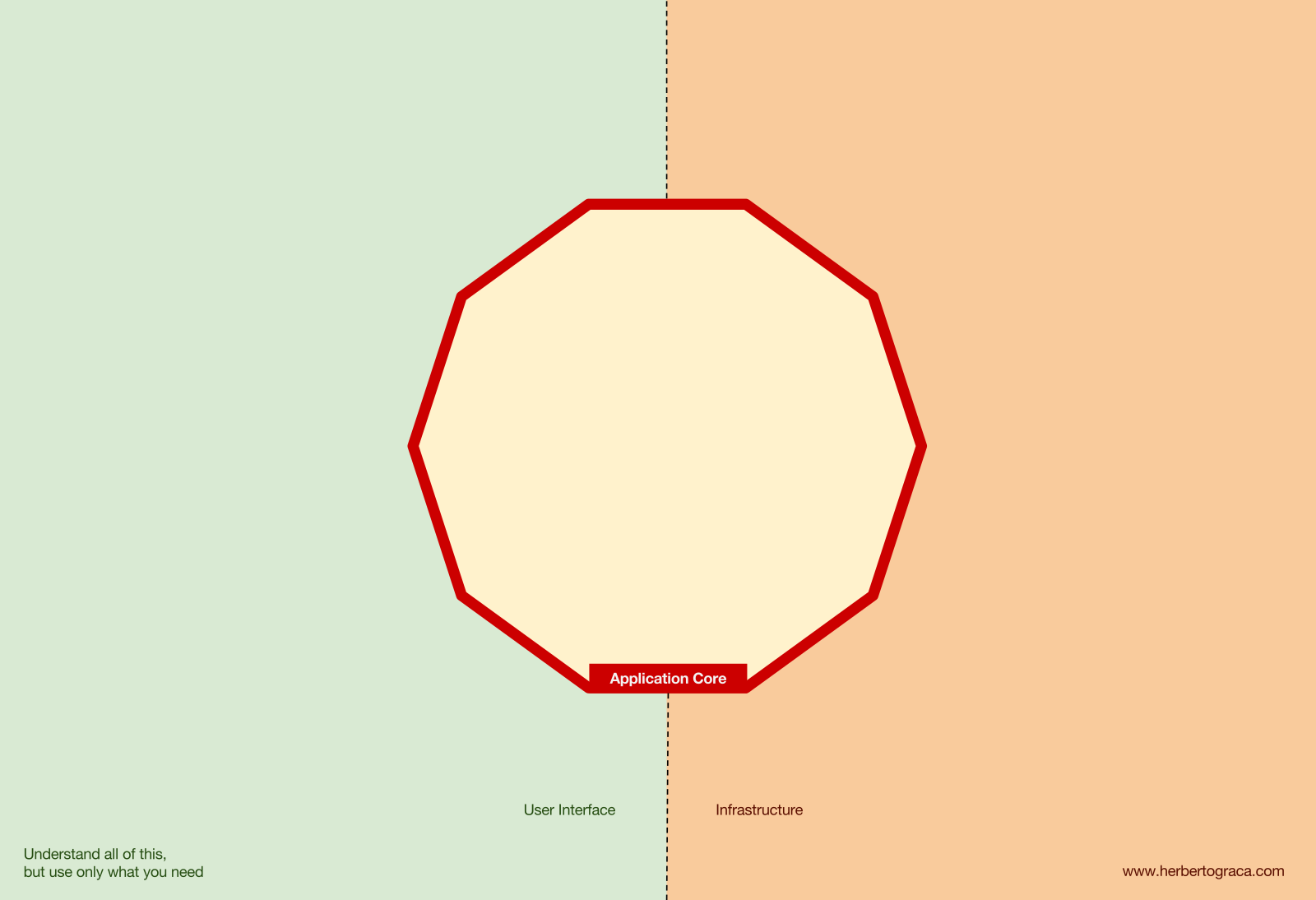
It starts with a view of the fundamental blocks of the system: user interface, application core and infrastructure.
It then progresses to cover the flow of control, primary and secondary drivers and inversion of control principle.
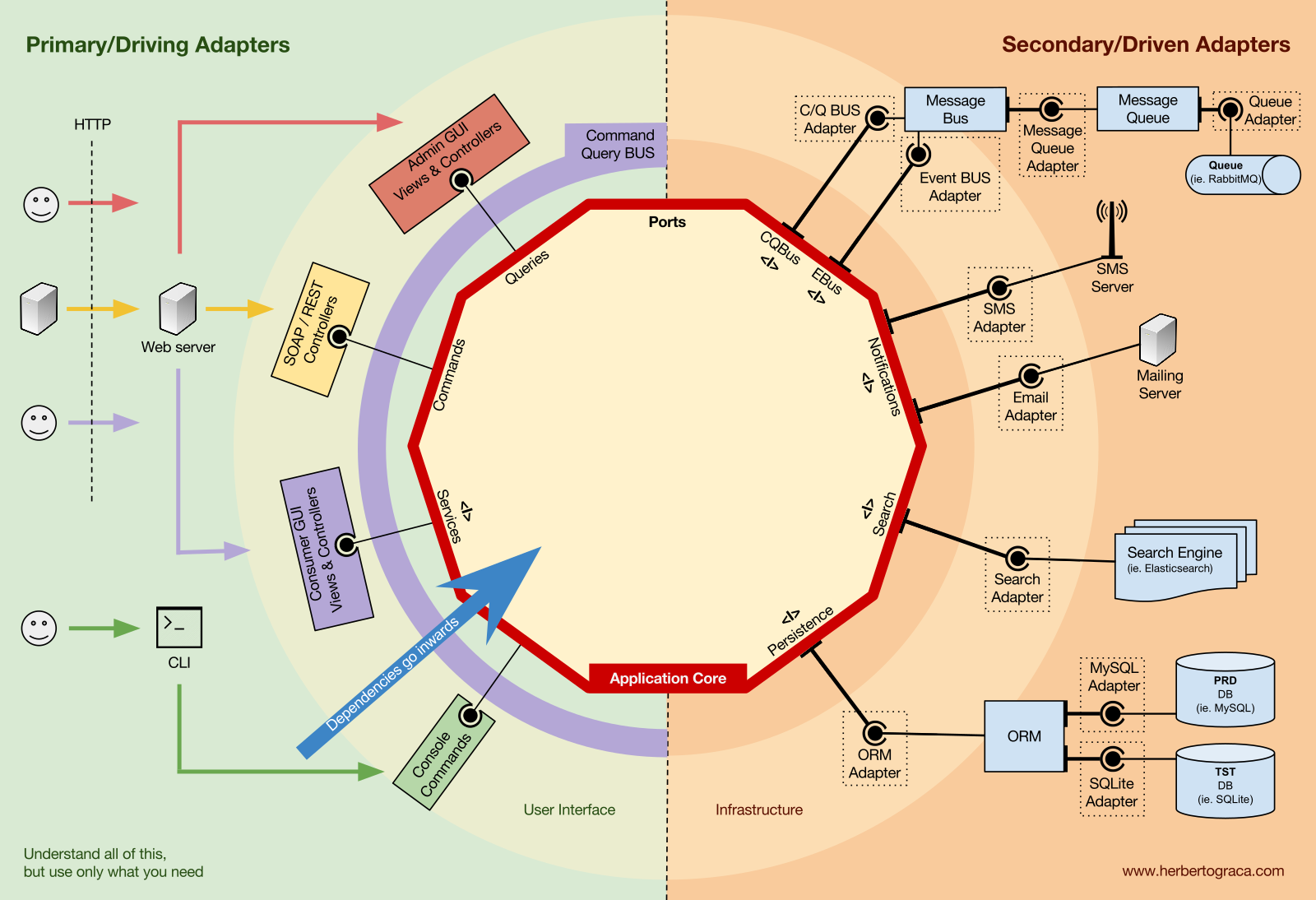
It passes to cover the application and domain layers, reaching a final view where all pieces fit together.
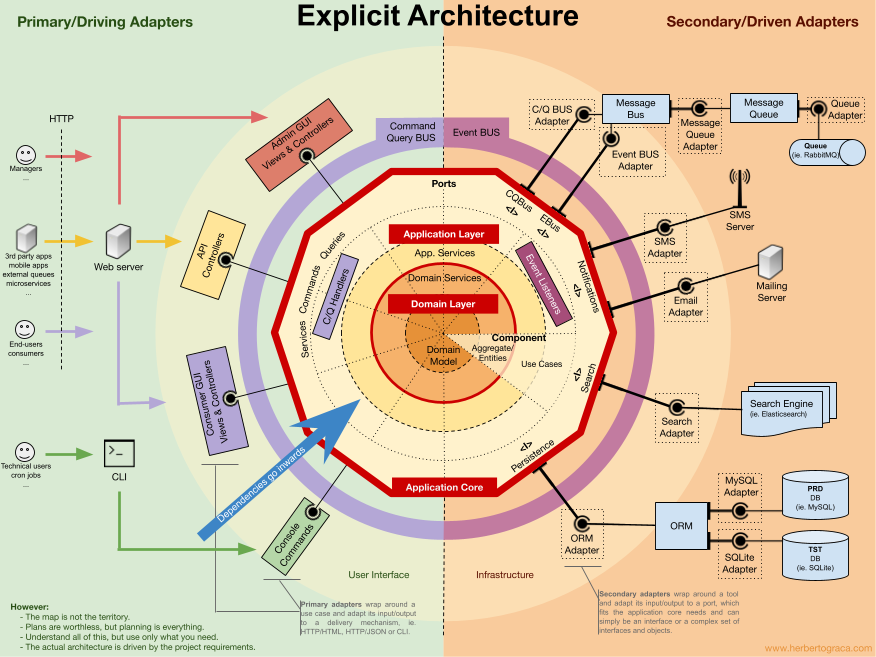
And, not it doesn´t mean you have to use all the elements you see in the final picture but if you follow the explanation, then this becomes a handy cheat sheet/guide to help you with a recurring question: where should I add this piece of code.
AI
7 Essential Generative AI Concepts for Solutions Architects
The popularization of generative AI presents challenges for architects who need to understand the various ways in which we can incorporate GenAI into the solutions we design.
Databases, messaging, and application servers are well-known, but now we have to consider foundational models (FM) and AI workflows with RAG, vector databases, etc. Using them follows patterns that depart from those of more "traditional" infrastructure.
Security takes another dimension when you factor that carefully created prompts can lead to the exposure of protected information, via attacks known as prompt injection.
Privacy now needs to consider that the information provided to the FM could be used for training, potentially being exposed to others.
Estimating costs means understanding token consumption for both input and output of LLMs.
Controlling costs and performance requires leveraging a more complex caching and choosing the models to be used wisely.
High availability and disaster recovery now need to factor in your AI workloads, model inference availability, and prompt caching.
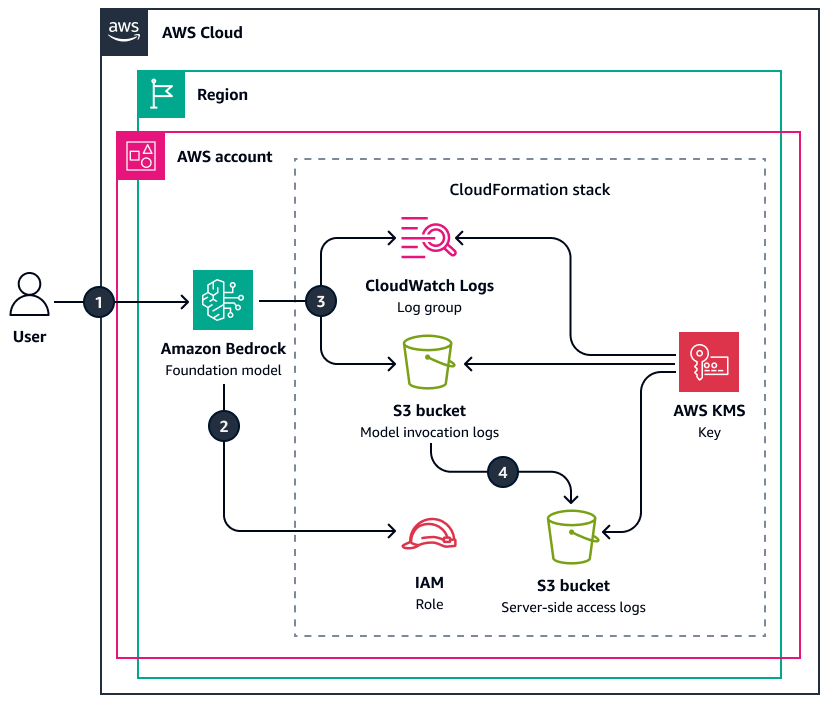
If you are an AWS shop, this article covers some training resources that can help you dig deeper into each one of them.
Quote
“Working with an LLM is like asking my kids to do chores: they do the first, forget the second and hallucinate the third!” - Me